
The best cron job monitoring tools are Hyperping (cron monitoring, uptime, on-call, and status pages at a flat rate), Healthchecks.io (free open-source heartbeat monitoring), Cronitor (schedule-aware cron analytics), Better Stack (monitoring with integrated logs and incidents), and UptimeRobot (budget-friendly uptime with basic heartbeat checks). I analyzed 25 tools total and narrowed it to these five based on hundreds of G2, Capterra, and Reddit threads, product research, and conversations with DevOps teams running scheduled jobs in production.
Most teams shopping for cron job monitoring are escaping the same situation: a backup, ETL, or billing job exited cleanly for days while doing nothing useful, and nobody noticed until a customer or downstream system complained. Basic logging and exit-code checks miss this entirely. A purpose-built tool catches missed runs, late starts, duration drift, and silent successes before they compound.
In this guide, you'll learn:
- What cron job monitoring actually is (and why plain logging isn't enough)
- What users on Reddit and review sites are really asking for (silent successes, context-rich alerts, schedule awareness)
- Five tools that each solve a different slice of the problem
- Honest pricing comparisons with actual numbers
- How to match a tool to your team size, technical depth, and budget
If you want one tool that catches missed cron jobs in 30 seconds, escalates through on-call rotations, and gives customers a branded status page when things break, Hyperping covers the full surface area. Schedule a demo to see it in action.
Key takeaways
- Hyperping is the most cost-effective bundle at $24/mo flat-rate: cron and heartbeat monitoring, uptime checks, on-call scheduling, and status pages with no per-user fees.
- Healthchecks.io is the best free open-source option for simple heartbeat monitoring, with a generous 20-check SaaS free tier and a BSD-licensed self-hosted option.
- Cronitor offers the deepest schedule-aware analytics with cron expression parsing, job duration tracking, exit code categorization, and crontab auto-import.
- Better Stack combines heartbeat monitoring with log management and incident response, helping you jump from "job failed" to "here's the log line that explains why."
- UptimeRobot is the budget pick, with a 50-monitor free tier and paid plans from $7/mo that bundle basic heartbeat checks alongside uptime monitoring.
Why you should trust this guide
I'm Léo, founder of Hyperping. Yes, that means I have a stake in one of these tools. But I've watched teams pick competitors when they were the better fit, and I'm not going to pretend otherwise. My goal isn't to convince you Hyperping is always the answer. It's to help you understand which tool actually solves your problem.
I analyzed hundreds of reviews on G2 and Capterra, dug through Reddit threads in r/devops, r/SaaS, r/sysadmin, and r/selfhosted where engineers discuss real production cron failures, tested platforms myself, and talked to DevOps teams about their setups. Where I couldn't test something directly, I leaned on verified user feedback and documented sources.
What is cron job monitoring?
Cron job monitoring is the practice of confirming that scheduled tasks (cron jobs, systemd timers, Kubernetes CronJobs, Windows Task Scheduler entries, background workers) actually ran and finished as expected. The standard model is heartbeat-based: the job sends an HTTP ping at the start, end, or both. If the expected ping doesn't arrive within a grace window, the monitoring tool alerts you.
A good cron monitoring tool catches four classes of failure:
- Missed runs: The job didn't execute at all (cron daemon down, server rebooted, container crashed).
- Late starts: The job ran but well after its expected time, often a sign of resource contention.
- Duration drift: A normally 5-second job now takes 45 seconds, an early warning of data growth or upstream issues.
- Silent successes: The job exited cleanly but did nothing useful (zero rows processed, backup early-returned on a stale lock file).
The first three are well covered by heartbeat tools. The fourth is the hardest, and most teams solve it by attaching context (logs, exit codes, JSON metadata) to each ping so alerts contain enough to debug without SSH'ing into a server.
Top picks at a glance
| Best for | Product |
|---|---|
| Cron + uptime + on-call + status pages at a predictable price | Hyperping |
| Free open-source heartbeat monitoring | Healthchecks.io |
| Deep schedule-aware cron analytics | Cronitor |
| Unified monitoring, logs, and incident management | Better Stack |
| Budget uptime monitoring with basic heartbeat checks | UptimeRobot |
What teams are actually looking for
Before getting into individual tools, it's worth grounding the comparison in what real users say they need. The recurring asks from Reddit threads in r/devops and r/SaaS, plus G2 and Capterra reviews, fall into a tight set of themes.
Catching silent failures, not just missed pings
The single most-repeated complaint I came across: a job pings "success" and exits 0, but does nothing useful. A backup script early-returns because a lock file is stuck. A scraper fetches zero new rows. A data processor handles an empty queue and reports success. One r/SaaS thread on what cron monitoring tools are still bad at made this the central question.
Pure heartbeat monitors can't see this. The closest fix is attaching context (exit codes, JSON payloads, log snippets) to each ping so alerts include actionable detail. Tools differ widely in how well they support this.
Schedule-aware logic that handles real cron expressions, timezones, and DST
Naive interval checking ("alert if no ping in 60 minutes") drifts against real cron schedules and breaks across DST changes. Users want tools that parse actual cron expressions, know the timezone, and calculate the next expected ping correctly. This is where Cronitor pulls ahead of simpler tools.
Context in alerts
"Job X failed" without logs, stderr, or exit codes leaves engineers right back at the SSH prompt. Reviews repeatedly call out tools that pass attached output forward in the alert payload, and grumble at tools that only say "no ping received."
Schedule and noise calibration
Some setups alert on every miss, which trains people to ignore them. Others wait too long. The pattern users want: "one miss is noise, three in a row is a real problem." Grace periods, retry windows, and per-job thresholds all matter, and tools differ on how granular this control is.
Predictable pricing at scale
Per-monitor pricing climbs fast when a team has 100+ jobs. Several Capterra reviewers explicitly call this out: Cronitor's per-monitor model is fine at 20 jobs and painful at 200. Datadog and similar broad-platform pricing, billed per host, feels exorbitant for what is, at its core, a small handful of HTTP pings.
Ease of setup and minimal code changes
The bar most teams expect: one curl command at the start and end of a job. Library calls for Python, Ruby, Node, and Go are nice but not required. Tools that demand heavy SDKs or agent installs lose ground here.
Quick comparison: cron job monitoring tools
| Tool | Starting Price | Best For | Main Limitation |
|---|---|---|---|
| Hyperping | $24/mo (50 monitors) | SMBs wanting cron + uptime + on-call + status pages | Not a full observability platform |
| Healthchecks.io | Free; paid from $20/mo | Simple heartbeat monitoring, self-hosting option | No uptime, no status pages, no on-call |
| Cronitor | From $10/mo | Deep cron analytics with schedule awareness | Per-monitor pricing climbs at scale |
| Better Stack | $29/mo | Teams wanting monitoring, logs, and incidents unified | Modular pricing adds up quickly |
| UptimeRobot | From $7/mo | Budget teams needing uptime with basic heartbeat checks | No on-call, basic cron features |
Hyperping: Best for cron monitoring with uptime, on-call, and status pages
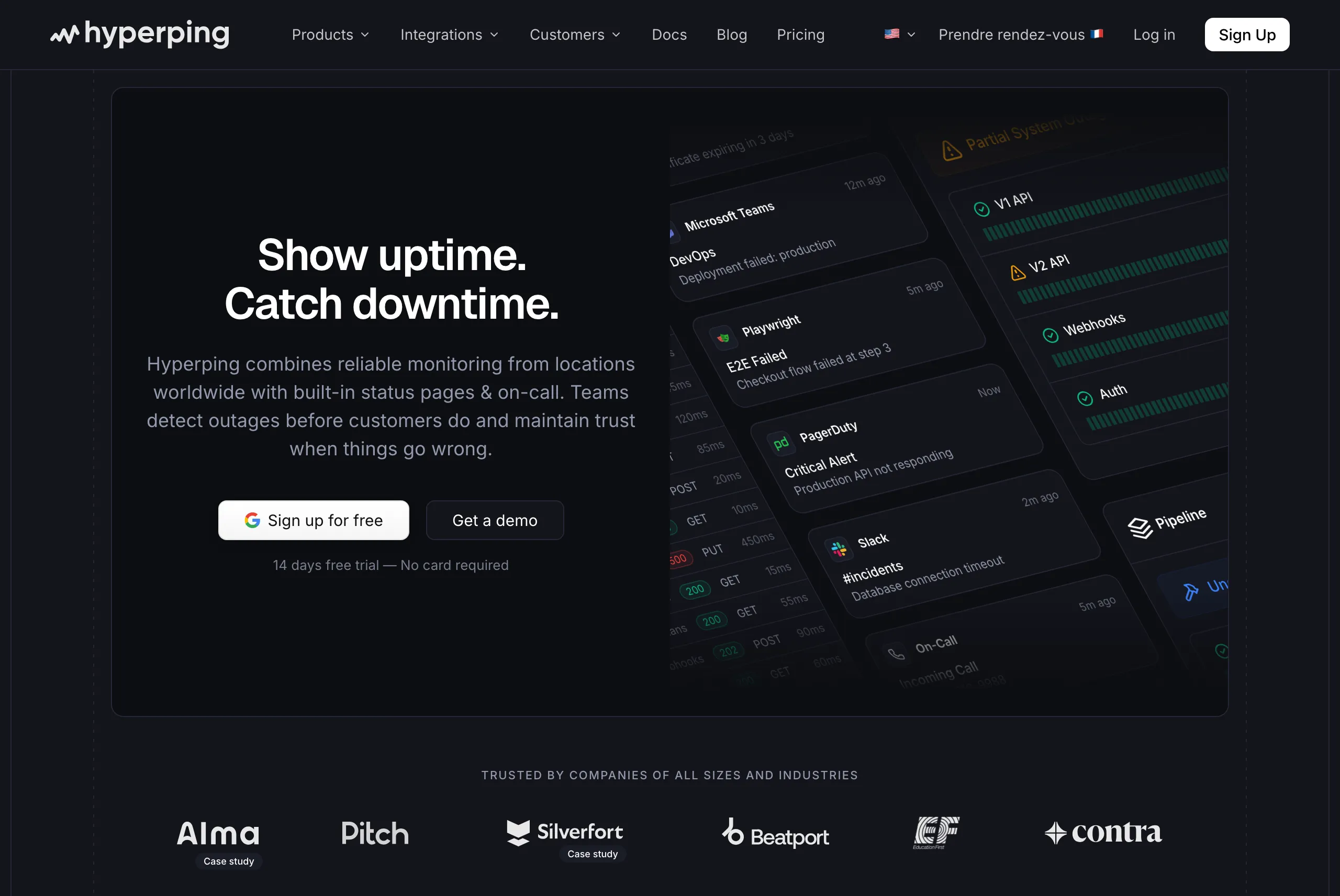
Who Hyperping is built for
Teams that started with a simple heartbeat tool and now need uptime checks, on-call scheduling, and status pages in one tool with predictable pricing. Hyperping focuses on doing the essentials well rather than adding every possible feature.
From the reviews and conversations I analyzed, Hyperping resonates with teams that value simplicity and flat-rate pricing. It's popular with European companies because it's a French company with EU hosting, and with growing SaaS teams that need more than a basic heartbeat monitor but don't want a full observability suite.
Notable features
- Cron job and heartbeat monitoring: Standard HTTP ping model. Jobs send a ping on start and finish, and Hyperping alerts when expected pings don't arrive within the grace window.
- 30-second uptime checks: Default check frequency for HTTP, HTTPS, TCP, and SSL monitoring. Business plans support sub-30-second intervals.
- On-call scheduling and escalation policies: Timezone-aware rotations, automatic schedule changes, and multi-step escalation. Most pure-heartbeat tools don't offer this at all.
- Voice call alerts: Phone calls for critical incidents, not just Slack or email.
- Full-featured status pages: Custom domain, white-label branding, multi-language support, and subscriber notifications. Included in plans rather than billed per page.
- Browser-based synthetic monitoring: Playwright tests for checkout, login, and other critical user flows.
- Agent-based server monitoring: a one-line agent install reports CPU, memory, filesystem, disk I/O, and network metrics from the boxes running your jobs, so a full disk shows up before the job dies.
- European hosting: GDPR-compliant infrastructure with EU data residency.
Why choose Hyperping for cron monitoring?
One tool instead of three
If you're running a heartbeat monitor plus a separate uptime tool plus a separate status page tool, Hyperping bundles all three. For a team with 50 cron jobs, 20 uptime checks, and a public status page, you'd typically need Healthchecks.io ($20/mo) plus UptimeRobot ($7/mo) plus Instatus or Atlassian Statuspage ($20 to $79/mo). Hyperping's $24/mo Essentials plan covers the same surface area.
On-call scheduling and escalation built in
When a billing job fails at 3 AM, who gets paged? Most heartbeat tools route alerts to channels but don't manage rotations or escalation. Hyperping includes timezone-aware on-call rotations, multi-step escalation, and voice call alerts. No need for a separate PagerDuty or OpsGenie subscription.
Flat-rate pricing
No per-monitor or per-user fees. You know what you'll pay at the start of the month.
What actual Hyperping users say
"Hyperping has been a total game-changer for us. The service is reliable, easy to use, and incredibly feature-rich. I love that it constantly checks our site and alerts us right away if there are any issues."
"We made our Hyperping status page publicly available and it became a crucial part of our sales pitches. We are proud of our uptime and we love that we can share it with prospects and customers in such an easy way."
How much does Hyperping cost?
- Essentials: $24/month for 50 monitors, 1 status page, 3 browser checks, 2 seats
- Pro: $74/month for 100 monitors, 3 status pages, 10 browser checks, 5 seats
- Business: $249/month for 1000 monitors, 10 status pages, 20-second checks, 25 browser checks, 15 seats, priority support, and more.
All plans include cron and heartbeat monitoring, on-call scheduling, escalation policies, and voice call alerts. A free tier and 14-day trial are available on all paid plans.
Where Hyperping falls short
Hyperping isn't open-source and doesn't offer a self-hosted option. If self-hosting is a hard requirement, Uptime Kuma or self-hosted Healthchecks.io is still the better path.
Hyperping's heartbeat monitoring uses the standard ping-based approach. If you need deeper cron-specific features like schedule-aware timing analysis, exit code categorization, or crontab auto-import, Cronitor is more specialized.
Is Hyperping right for you?
Choose Hyperping if you want one tool for heartbeat monitoring, uptime checks, on-call, and status pages at a flat rate. It's a strong fit for growing SaaS teams, European companies that value GDPR-compliant hosting, and SMBs that need on-call scheduling without adding a separate incident response tool.
Healthchecks.io: Best for free open-source heartbeat monitoring
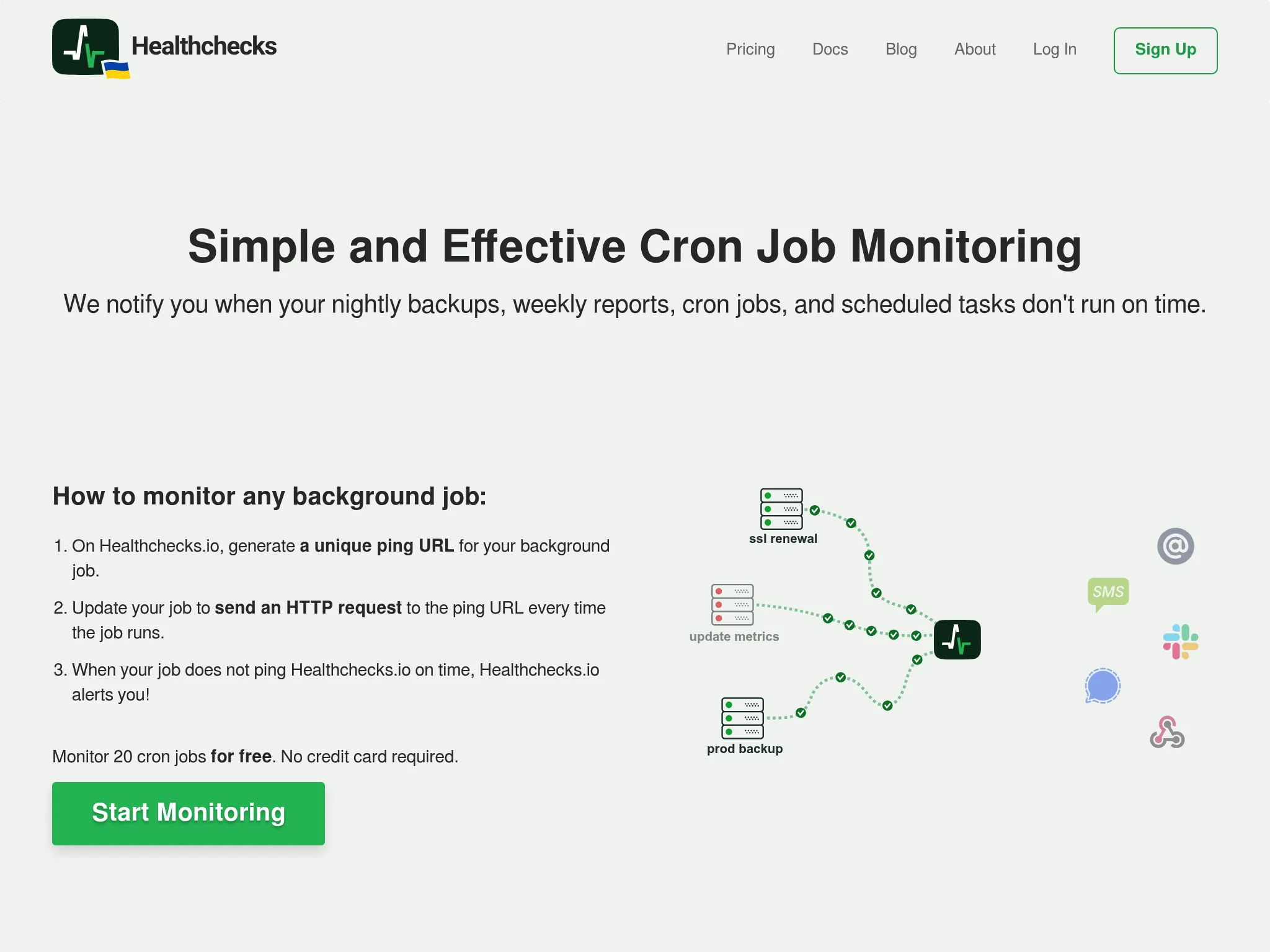
Who Healthchecks.io is built for
Developers and small teams that need reliable heartbeat monitoring for cron jobs and scheduled tasks without paying for features they won't use. Healthchecks.io is the most-recommended cron monitoring tool on r/selfhosted and r/devops, and it earns the praise: it does one thing very well.
Notable features
- Simple heartbeat monitoring: Each check gets a unique ping URL. Jobs call it when they complete. If a ping doesn't arrive within the expected window, you get an alert.
- Cron expression support: Define expected schedules using actual cron expressions. Healthchecks.io calculates when the next ping should arrive, accounting for timezones.
- Grace periods: Configure how long to wait after a missed ping before alerting, reducing noise from jobs that run slightly late.
- Start/finish pings: Send a ping at the start and another at the end to measure duration.
- Log attachment: Include up to 100 KB of stdout/stderr in the ping body for context in alerts.
- Multi-channel alerting: Email, Slack, Discord, Telegram, PagerDuty, OpsGenie, Microsoft Teams, webhooks, and 25+ other integrations.
- Open-source and self-hostable: BSD-licensed. Run your own instance if data sovereignty or cost control matters.
- Generous free SaaS tier: 20 checks with unlimited team members on the hosted version.
Why choose Healthchecks.io?
Free or significantly cheaper than most alternatives
20 free checks on SaaS with no time limit, or unlimited if you self-host. Paid plans start at $20/mo for 100 checks. For pure heartbeat monitoring, this is the cheapest tool that's actually good.
Self-hosting option
BSD-licensed and well-documented. Many r/selfhosted users run their own instance alongside Uptime Kuma for redundancy.
Focused simplicity
No feature bloat. The web UI does one thing, and it does it cleanly.
How much does Healthchecks.io cost?
- Free: 20 checks, unlimited team members, email and webhook alerts
- Hobbyist: $20/month for 100 checks
- Business: $80/month for 1000 checks, phone call and SMS alerts
- Business Plus: $320/month for 5000 checks
- Self-hosted: Free (BSD license), you provide the infrastructure
Where Healthchecks.io falls short
No uptime monitoring. It can't tell you whether your website is up, monitor SSL certificates, or check API response times.
No status pages. You'll need a separate tool like Instatus or Atlassian Statuspage if you want to communicate incidents publicly.
No on-call scheduling. Alerts go to configured channels, but there's no rotation or escalation logic.
Coarse statuses. A late ping and a failed exit code are treated similarly. Users running 100+ jobs on r/selfhosted often call out the lack of nuanced statuses (warning vs critical) as a reason to look elsewhere.
Setup leans on the web UI. Auto-provisioning via first ping creates a basic check but doesn't set the schedule, grace period, or channels. Random UUID URLs make declarative config awkward.
Is Healthchecks.io right for you?
Choose Healthchecks.io if heartbeat monitoring is your primary need and you want it done simply and affordably. It's a strong fit for developers on tight budgets, organizations that need self-hosted monitoring for data sovereignty, and teams that already have separate tools for uptime and status pages.
Cronitor: Best for deep schedule-aware cron analytics
Who Cronitor is built for
Engineering teams running hundreds of scheduled jobs that need more than "did it run?" Cronitor parses cron expressions, tracks job durations, categorizes exit codes, and detects timing anomalies. It's the most cron-specific tool on this list.
From the reviews I analyzed, Cronitor is popular with engineering teams at companies like Reddit, Square, and monday.com. The schedule-aware alerts and crontab auto-import are the features users mention most.
Notable features
- Schedule-aware heartbeat monitoring: Cronitor parses cron expressions and knows when each ping should arrive. Late, missed, and unexpected pings each get their own treatment, with proper handling of timezones and DST.
- Job duration and exit code tracking: Distinguishes between "ran successfully," "ran but exited non-zero," and "didn't run."
- Crontab auto-import: Point Cronitor at a server's crontab and it imports the schedules automatically.
- Anomaly detection on timing: Alerts when job duration drifts from the historical baseline.
- Telemetry pings: Send custom JSON metadata with each ping (rows processed, duration, error counts) for richer alerts.
- Uptime and RUM monitoring: Cronitor expanded beyond pure cron monitoring into uptime and real user monitoring.
Why choose Cronitor?
Nuanced job statuses
Simple heartbeat tools treat missed pings and failed exit codes the same way. Cronitor alerts on missed pings, late pings, failed exit codes, slow runs, and unexpected runs as separate events.
Setup that doesn't require clickops
Crontab auto-import and a clean API make it possible to manage monitors as code rather than clicking through the web UI for each job.
Deeper analytics
Timing trends, duration distributions, and anomaly flags. For teams managing 100+ jobs where "is this job slowly getting worse?" matters, the difference is meaningful.
How much does Cronitor cost?
- Hobbyist: Free, 5 monitors
- Startup: $10/mo, 10 monitors with full alerting and integrations
- Team: $50/mo, 50 monitors and team features
- Business: $2 per monitor per month plus $5 per user per month, with volume discounts at scale
The per-monitor pricing is the friction point. For 100 monitors and 5 users, the Business plan runs about $225/mo.
Where Cronitor falls short
Pricing climbs faster than flat-rate alternatives. Per-monitor plus per-user pricing means a team with 200 monitors and 5 users pays more than they would on Hyperping or Healthchecks.io's flat tiers.
No on-call scheduling. Like most heartbeat tools, Cronitor routes alerts but doesn't manage rotations or escalation.
Feature expansion has diluted the focus. Long-time users on Capterra have noted that the UI feels busier since Cronitor added uptime and RUM features.
Is Cronitor right for you?
Choose Cronitor if you want the deepest cron-specific analytics and you're comfortable with per-monitor pricing. It's a strong fit for teams running hundreds of scheduled jobs, organizations that need exit code and duration tracking, and anyone who wants crontab auto-import to skip the clickops setup.
Better Stack: Best for unified monitoring, logs, and incidents
Who Better Stack is built for
Engineering teams that want heartbeat checks, uptime monitoring, log management, and incident response in a single platform. Better Stack works well when you want to go from "the cron job failed" to "here's the log line that explains why" without switching tools.
From the G2 reviews I analyzed, Better Stack's strength is its polished developer experience. Users consistently call out the modern UI and fast setup. One reviewer described it as having "probably the best looking interface you'll ever get to work with."
Notable features
- Heartbeat monitoring: Cron job and background task checks with expected check-in intervals and alerts on missed pings.
- 30-second uptime checks: Verified from at least three geographic regions to reduce false positives.
- Integrated log management: SQL-like querying with ClickHouse-powered storage. When a job fails, you can search the logs from that job in the same platform.
- Incident management: On-call scheduling, escalation policies, and AI-generated post-mortems.
- Multi-channel alerting: Voice, SMS, Slack, Teams, email, and push notifications with noise suppression.
- Status pages: Public and private pages with branded communication.
Why choose Better Stack?
Logs alongside heartbeat alerts
When a job misses a ping or exits non-zero, Better Stack can show you the logs from that run in the same view. For teams that spend a lot of time tailing logs after a failed job, this is a real workflow improvement.
On-call scheduling and incident management included
Rotations, escalation, smart incident merging, and post-mortem timelines built in. If a nightly job fails, the alert reaches whoever is on-call, escalates if they don't acknowledge, and creates an incident record automatically.
Broader scope in one tool
Heartbeat plus uptime plus logs plus infrastructure metrics. For teams whose monitoring needs have grown beyond "did the job run," Better Stack provides more context in fewer tools.
What G2 users say about Better Stack
"BetterStack Uptime is an excellent tool for monitoring the availability of sites and services in real-time. Its interface is modern, easy to use, and pleasant on a daily basis. I appreciate the ability to quickly set up monitors, receive multi-channel alerts, and share professional status pages with clients."
How much does Better Stack cost?
Better Stack uses modular pricing that adds up across products:
- Free tier: 10 monitors, 1 status page, limited log retention
- Monitors: $21/month per 50 additional monitors
- On-call responders: $29/month per user
- Status pages: $12/month per page plus advanced addons
- Heartbeat monitors: $17/month per 10
Where Better Stack falls short
Pricing is hard to predict. The modular structure makes total cost difficult to estimate up front. What starts as a free tool can climb to $100 to $200/mo for a small team.
Heartbeat features are basic. Better Stack's heartbeat checks are interval-based. They don't parse cron expressions, track job duration, or detect timing anomalies the way Cronitor does.
No infrastructure metrics or APM. If you want full observability with metrics and traces, you'll still need a tool like Datadog or Grafana Cloud on top.
Is Better Stack right for you?
Choose Better Stack if you want monitoring, logging, and incident management together and you're comfortable with modular pricing. It's a strong fit for teams that debug job failures through logs, organizations that value a modern UI, and groups that want on-call alongside their checks.
UptimeRobot: Best for budget uptime with basic heartbeat checks
Who UptimeRobot is built for
Freelancers, solo developers, small teams, and agencies that need affordable uptime monitoring and want basic heartbeat checks bundled into the same tool. UptimeRobot has over 2.5 million users since 2010 and runs the most generous free tier in the category.
Notable features
- Multi-type monitoring: HTTP(S), ping, port, keyword, DNS, SSL certificate expiry, domain expiry, and cron/heartbeat monitoring.
- Generous free plan: 50 monitors with 5-minute check intervals.
- Status pages: Customizable public status pages with subscriber options.
- Multi-channel alerting: Email, SMS, voice calls, push notifications, webhooks, plus integrations with Slack, Teams, Discord, Telegram, Google Chat, and PagerDuty.
- Mobile apps: Native iOS and Android apps.
- REST API: Full automation for agencies managing many monitors.
Why choose UptimeRobot?
Heartbeat plus uptime in one cheap tool
If your cron monitoring needs are modest and you also want HTTP, ping, SSL, and DNS checks for your services, UptimeRobot is the cheapest way to cover both. The free tier covers 50 monitors, and Solo at $7 to $8/mo adds 1-minute checks and SSL expiry monitoring.
Status pages included on paid plans
UptimeRobot includes customizable status pages on paid tiers, which Healthchecks.io and most pure-heartbeat tools don't.
Voice call alerts on paid plans
Phone calls for critical incidents, not just Slack or email.
What G2 users say about UptimeRobot
"Uptime Robot is a reliable service that I used for about 8 years to monitor the uptime of my application and its services. It has quite a rich feature set where it comes to setting up the monitor requests, is easy to use and allows the creation of very attractive status pages."
"UptimeRobot is very easy to set up and doesn't require much technical knowledge to get started. The free tier already covers the most important monitoring needs, which makes it perfect for smaller projects or first use cases."
How much does UptimeRobot cost?
- Free: 50 monitors, 5-minute intervals, basic status pages, limited integrations
- Solo: roughly $7 to $8/month, 1-minute checks, SSL and domain expiry monitoring, more integrations
- Team: roughly $28/month, all integrations, full-featured status pages, multiple seats
- Enterprise: Custom pricing
Annual billing saves about 20%.
Where UptimeRobot falls short
Basic cron features. UptimeRobot's heartbeat monitoring works but lacks Cronitor's schedule-aware logic, cron expression parsing, job duration tracking, and exit code categorization. If cron-specific depth is your priority, this isn't the right tool.
No on-call scheduling. Alerts go to configured channels, but there's no rotation or escalation logic.
No synthetic monitoring. UptimeRobot can't test multi-step user flows or browser rendering.
Limited diagnostics. UptimeRobot tells you something is down but doesn't help you figure out why. No log attachment, no APM, no RUM.
Is UptimeRobot right for you?
Choose UptimeRobot if you need affordable monitoring for many endpoints and basic heartbeat checks are good enough for your cron jobs. It's a strong fit for freelancers monitoring client sites, agencies that need the most monitors per dollar, and personal projects on a tight budget. If cron-specific depth or on-call scheduling matters, look at Cronitor or Hyperping.
Open-source alternatives: self-hosted Healthchecks.io and Uptime Kuma
If self-hosting is a hard requirement, two options stand out:
- Healthchecks.io is BSD-licensed, well-documented, and the cleanest self-hosted match for the heartbeat model. Docker images and community guides are plentiful.
- Uptime Kuma is MIT-licensed and broader in scope: heartbeat checks plus HTTP, TCP, DNS, and SSL checks plus public status pages out of the box.
A common r/selfhosted setup is to run both: Uptime Kuma for active uptime checks and self-hosted Healthchecks.io for pure heartbeats. Some users monitor their Healthchecks.io instance with Uptime Kuma for redundancy.
The tradeoff with self-hosting: you are the single point of failure. If your monitoring server is down, you won't know when your services fail. There's no global probe network to verify outages from multiple locations. For most teams past a certain size, the reliability of managed services outweighs the cost savings.
All cron job monitoring tools analyzed
For completeness, here's the broader landscape beyond the top picks:
| Name | Pricing (2026 Est.) | Main Strength | Main Weakness |
|---|---|---|---|
| Hyperping | From $24/mo | Bundled scope. Cron, uptime, status pages, on-call without per-user fees. | Not full observability. No logs or APM. |
| Healthchecks.io | Free; from $20/mo | Open-source and self-hostable. Simple, generous free tier. | Heartbeat only. No uptime, status pages, or on-call. |
| Cronitor | From $10/mo | Cron depth. Schedule awareness, duration tracking, exit code categorization. | Per-monitor pricing climbs at scale. |
| Better Stack | $29/mo | Unified platform. Monitoring with logs and incidents. | Pricing jumps. Modular pricing adds up. |
| UptimeRobot | From $7/mo | Budget uptime with basic heartbeat checks included. | Basic cron features and no on-call. |
| Dead Man's Snitch | From $19/mo | Simplicity. Fastest setup, stable for over a decade. | Limited features beyond pure heartbeat. |
| Cronhub | From $10/mo | Schedule awareness with cron expression parsing and team features. | Smaller user base, slower roadmap. |
| Uptime Kuma | Free (self-hosted) | Self-hosted polish. Free, MIT, broader check types. | You're the SPoF. No global probes. |
| Sentry Crons | Free with Sentry; usage-based | Tight error tracking integration for teams already on Sentry. | Requires Sentry for full value. |
| PagerDuty | From $21/user/mo | On-call gold standard. Best-in-category escalation workflows. | No native heartbeat monitoring. |
| Datadog | From $15/host/mo | Full observability. Metrics, logs, traces, and cron in one suite. | Expensive and overkill for simple cron monitoring. |
| New Relic | Free tier; $49/user/mo | User-based pricing for full platform access. | Steep learning curve, ingestion costs. |
| Site24x7 | From ~$9/mo | Value for money. RUM, APM, server, network at low price. | Dated UI. Interface is cluttered. |
| Checkly | Free; $24/mo | Programmable synthetics. Playwright in CI/CD. | Requires coding. Not for non-technical users. |
| StatusCake | Free; $24.49/mo | Page speed. Includes Lighthouse data. | Slower development cadence. |
| Grafana Cloud | Free; usage-based | Visualization. Top-tier dashboarding. | Complexity. Steep PromQL/LogQL learning curve.** |
Frequently asked questions
What's the difference between cron job monitoring and uptime monitoring?
Uptime monitoring is active: a tool sends a request to your service and checks the response. Cron job monitoring is passive: your job sends a ping to the tool, which alerts when expected pings don't arrive. You usually want both. Uptime monitoring catches "your website is down." Cron monitoring catches "your nightly backup didn't run."
Do I need a dedicated cron monitoring tool if I already use Datadog or New Relic?
You can do heartbeat monitoring inside both, but it's often overkill for the use case and expensive at scale. Teams that already pay for Datadog for application metrics sometimes still pick a dedicated cron tool because the dedicated tools are simpler, cheaper per check, and easier to hand off to engineers who don't live in Datadog day-to-day. If the per-host bill is what sent you looking, the server monitoring cost calculator shows what Datadog, New Relic, Netdata, and Hyperping cost at your host count.
Can I monitor systemd timers, Kubernetes CronJobs, and Windows Task Scheduler the same way?
Yes. Every tool on this list works with any system that can make an HTTP request. systemd timers can call curl in an ExecStart, Kubernetes CronJobs can include a curl in their command, and Windows Task Scheduler tasks can run a PowerShell script that invokes Invoke-WebRequest. The monitoring tool doesn't know or care what scheduled the job.
How do I catch silent failures where the job exits 0 but does nothing?
Three approaches: (1) Have the job ping a failure endpoint when it produces zero results or hits a known empty condition. (2) Attach JSON metadata to each ping (rows processed, files written, bytes transferred) and alert on anomalies. (3) Track duration: a normally 30-second job that finishes in 2 seconds is a strong signal that something is off. Cronitor and Hyperping support the metadata and anomaly cases. Healthchecks.io supports log attachment but relies on you to wire up the logic.
Is there a free cron job monitoring tool?
Yes. Healthchecks.io offers 20 free checks on SaaS with no time limit, or unlimited if you self-host. UptimeRobot has a 50-monitor free tier. Uptime Kuma is free and self-hosted. Hyperping has a free tier with 20 monitors. Better Stack and Cronitor each offer free tiers with 10 and 5 monitors respectively.
Which cron monitoring tool is best for small teams?
For pure simplicity on a tight budget, Healthchecks.io or UptimeRobot. For teams that also need uptime monitoring, a status page, and on-call in one tool, Hyperping bundles all three at $24/mo. For teams that want logs alongside cron alerts, Better Stack's free tier covers a lot before paid plans kick in.
Which cron monitoring tool is best for large teams or enterprises?
Cronitor for deep cron analytics at scale. Better Stack for unified monitoring and incident response. Hyperping's Business plan for teams that want flat-rate pricing across 1000 monitors with on-call included. Datadog or New Relic if cron monitoring is one slice of a broader observability buy.
How to test these tools
All five top picks offer trials or free tiers:
- Hyperping: Free tier and 14-day trial on all paid plans
- Healthchecks.io: Free SaaS tier with 20 checks, or self-host for free
- Cronitor: Free Hobbyist tier with 5 monitors
- Better Stack: Generous free tier with monitoring, logging, and status pages
- UptimeRobot: Free plan with 50 monitors
To evaluate them:
- Pick three real cron jobs of different criticality (a backup, a nightly ETL, a periodic cleanup) and configure each tool to monitor them in parallel.
- Trigger a deliberate failure: stop one job entirely, make another exit non-zero, and slow a third one down. Compare detection speed and alert quality.
- Test the alerting workflow end to end: does the alert reach the right person, through the right channel, fast enough? If on-call matters, exercise the escalation path.
- Evaluate the dashboard for what you actually need: ping history, timing trends, exit code categorization, log attachment.
- Compare total cost at your expected monitor count, including any tools you'd consolidate. A $24/mo bundled tool that replaces $20 + $7 + $20 of separate services is often the right call even if its monitor count is lower.
Related reading
- Migrate from UptimeRobot to Hyperping — step-by-step migration guide
- Migrate from Better Stack to Hyperping — step-by-step migration guide
- Best Cronitor alternatives — if cron monitoring is your primary concern
- Linux server monitoring guide: catch the full disks and memory pressure that kill scheduled jobs



