
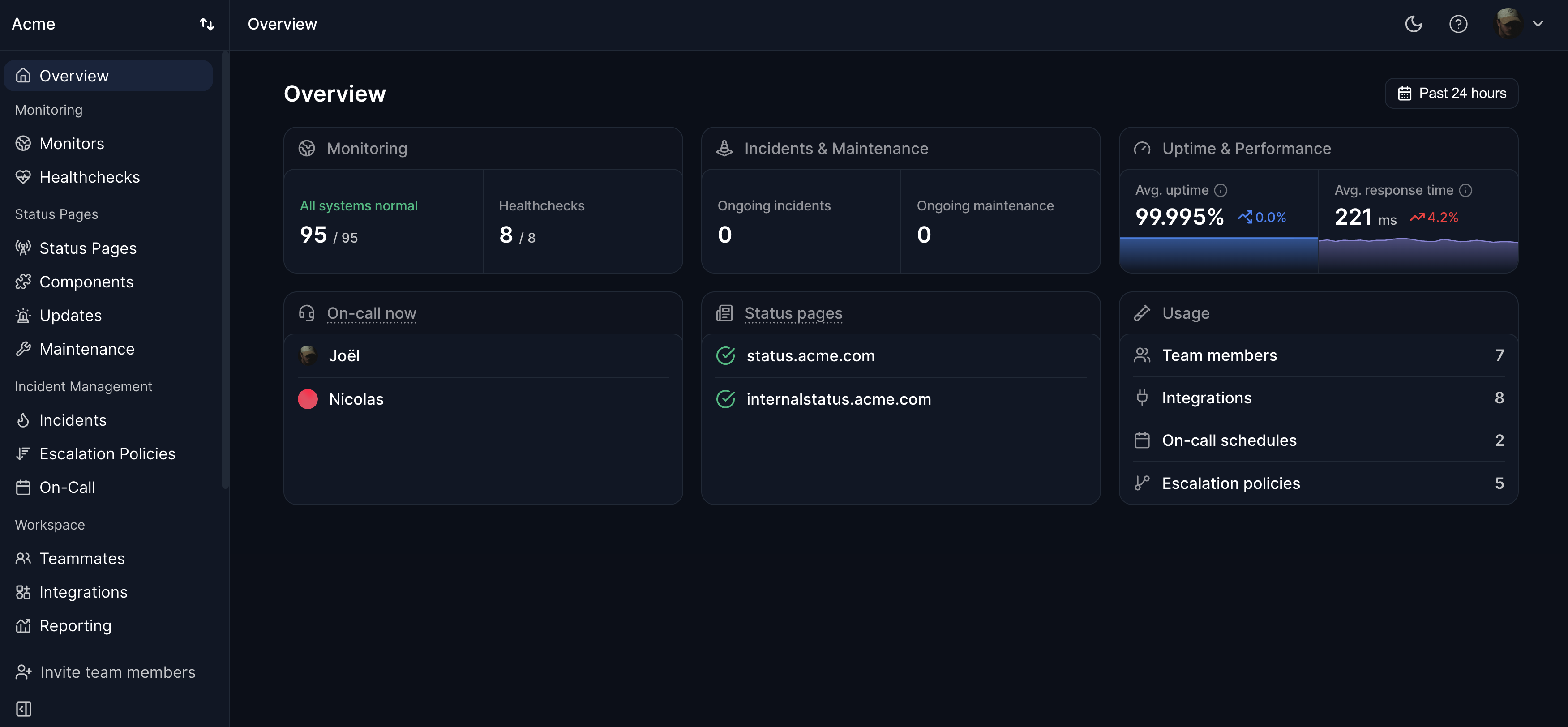


Stop juggling tools during
your most stressful moments
Before Hyperping
After Hyperping
Multi-step escalation
Define escalation chains with time-based triggers. If nobody acknowledges within 5 minutes, escalate to the next level via a different channel.
On-call scheduling
Calendar-based rotations with multiple layers. Daily, weekly, or custom schedules ensure someone is always available to respond.
Alert grouping
Group related alerts to reduce noise during large incidents. One notification for correlated failures instead of an alert storm.
Multi-channel alerting
Route alerts to Slack, Teams, SMS, phone calls, email, Discord, PagerDuty, or webhooks. The right people get notified on the right channel.
Status page updates
Push incident updates to your public status page simultaneously. Keep customers informed without switching tools or contexts.
Third-party integrations
Connect to PagerDuty, Opsgenie, and Jira Service Management for bi-directional incident sync. Works with your existing tools.
Automated detection
Hyperping monitors your services and automatically creates incidents when outages are detected. No manual intervention needed for known failure modes.
Manual incident reporting
Declare incidents directly from the dashboard with severity levels, descriptions, and immediate team notification. For issues your monitoring may not catch.
Severity classification
Classify incidents as Critical, Major, or Minor to ensure the right response. Severity drives escalation behavior and notification urgency.
Acknowledgment tracking
Know who has seen and acknowledged each incident. Track response times to identify bottlenecks in your incident response process.
Duration tracking
Automatic timing from detection to resolution. Measure MTTA and MTTR across your team, then turn any incident into a blameless post-mortem with our free generator.
Maintenance windows
Schedule maintenance ahead of time and suppress false alerts during planned work. Keep your status page updated and customers informed automatically.
Legacy Stack vs. Hyperping
Legacy Stack
+ time spent integrating & context-switching

"Hyperping's reputation in our company is that it's more reactive than Datadog. We usually get notifications from Hyperping before Datadog."
