Reliable, high-performing systems are the lifeblood of modern digital businesses.
But it's hard to know where to start, especially when you're a startup with limited resources and a small DevOps or SRE team.
Fortunately, effective continuous testing doesn't have to be overly complicated.
In this guide, we'll break down the essential components of continuous testing in DevOps, with special attention to the often-overlooked monitoring aspect that can make or break your testing strategy.
What is continuous testing in DevOps and why is it important?
Continuous testing is the process of executing automated tests as part of the software delivery pipeline to obtain immediate feedback on business risks associated with the latest build.
Unlike traditional testing, which happens at specific phases, continuous testing occurs throughout the entire development lifecycle.
Continuous testing is essential in the DevOps world for several reasons:
- Accelerates software delivery — By automating tests and running them continuously, teams can identify and fix issues much faster than with manual testing approaches
- Improves software quality — Regular testing throughout the development process means fewer defects make it to production
- Reduces business risk — Early detection of issues that could impact users or business operations
- Enables continuous feedback — Provides development teams with immediate insights about code quality and functionality
- Supports DevOps culture — Breaks down silos between development and operations by making quality everyone's responsibility
While continuous testing is clearly valuable, many DevOps teams struggle to implement it effectively. A common mistake is focusing exclusively on pre-deployment testing while neglecting what happens after code reaches production.
True continuous testing extends beyond deployment and includes monitoring your systems in production to ensure they're performing as expected. This is where many testing strategies fall short.
The continuous testing lifecycle
To implement continuous testing successfully, you need to understand how it fits into the broader DevOps lifecycle. Here's a step-by-step breakdown:
1. Define your testing strategy
Before writing a single test, determine what needs to be tested, how often, and what metrics will indicate success. Your strategy should align with business goals and account for available resources.
This means identifying critical paths in your application, determining acceptable performance thresholds, and establishing clear pass/fail criteria for your tests.
2. Integrate testing into your CI/CD pipeline
Continuous testing requires automation. Tests should run automatically whenever code changes are submitted, providing immediate feedback to developers.
Your CI/CD pipeline should include various test types, from unit tests that verify individual components to integration tests that ensure different parts of your system work together correctly.
3. Test in production-like environments
One of the biggest challenges in testing is ensuring your test environments accurately reflect production. Container technologies like Docker and orchestration tools like Kubernetes have made this easier, allowing teams to create consistent environments across development, testing, and production.
Testing in environments that closely mimic production helps identify issues that might only appear under real-world conditions, reducing nasty surprises after deployment.
4. Analyze results and iterate
Continuous testing generates a wealth of data. Analyzing this data helps you identify patterns, improve your tests, and refine your overall approach.
Pay special attention to trends over time. Are certain types of issues recurring? Are specific components consistently problematic? This information is invaluable for improving both your testing strategy and your application.
5. Extend testing into production
This is where monitoring comes in.
Once code is deployed, you need continuous visibility into how it's performing. This means monitoring key metrics, setting up alerts for anomalies, and having systems in place to quickly respond to issues.
Production monitoring is essentially a form of continuous testing that never stops. It's your safety net for catching issues that slipped through pre-deployment testing.
Continuous monitoring acts as your early warning system, alerting you to issues before they affect users and providing data to improve future development cycles. It helps you quickly respond to issues when they arise.
Types of continuous testing in DevOps
A comprehensive continuous testing approach incorporates various testing types (you can find a detailed overview of software testing types here). Each serves a specific purpose in ensuring your systems are reliable and perform as expected.
- Unit testing — Verifies that individual components work as expected in isolation, providing fast feedback to developers and encouraging modular code
- Integration testing — Ensures different components work together correctly, catching interface issues and verifying data flow through the system
- Functional testing — Validates that the system meets user requirements by testing end-to-end workflows and business logic
- Performance testing — Evaluates how the system performs under various conditions, identifying bottlenecks and ensuring it meets performance requirements
- Security testing — Identifies vulnerabilities and ensures the system protects sensitive data, reducing the risk of breaches
- Reliability testing — Ensures the system remains available and performs consistently over time, verifying it can maintain service level agreements
While all these testing types are important, reliability testing often receives less attention than it should, despite being critical for maintaining user trust and meeting business objectives.
Continuous monitoring: The often overlooked component of continuous testing
Many DevOps teams mistakenly believe testing ends once code is deployed to production. In reality, production is where some of the most important testing happens through continuous monitoring.
Why monitoring is essential for continuous testing
Production environments introduce variables that are difficult or impossible to simulate in pre-production testing:
- Real user behavior and traffic patterns
- Interaction with third-party services under real conditions
- Edge cases that only emerge at scale
- Long-running processes that may develop issues over time
Continuous monitoring acts as your early warning system, alerting you to issues before they affect users and providing data to improve future development cycles.
Key monitoring approaches for DevOps teams
Uptime monitoring
The most fundamental form of monitoring is simply checking if your services are available. Uptime monitoring periodically sends requests to your endpoints and alerts you if they fail to respond or return unexpected results.
Effective uptime monitoring should:
- Check multiple endpoints across your application
- Run from different geographic locations to detect regional issues
- Monitor at appropriate intervals based on criticality
- Include SSL certificate monitoring to prevent unexpected expirations
Tools like Hyperping offer comprehensive uptime monitoring with features specifically designed for DevOps teams, including browser checks that simulate user interactions, not just simple ping tests.
Performance monitoring
Beyond basic availability, you need to monitor how well your system is performing. Slow responses can be just as problematic as outages for many applications.
Key performance metrics to monitor include:
- Response times
- Error rates
- Resource utilization (CPU, memory, disk, network)
- Database query performance
- Third-party service response times
Cron job monitoring
For DevOps teams, background jobs and scheduled tasks are often critical components of the system that can fail silently. Monitoring these tasks ensures they're running successfully and at the expected times.
Hyperping's cron job monitoring provides visibility into these otherwise hidden processes, alerting you if jobs fail to run or complete successfully.
Log monitoring and analysis
Logs contain valuable information about system behavior and can provide early indicators of developing issues. Effective log monitoring involves:
- Centralizing logs from all components
- Implementing structured logging
- Setting up alerts for error patterns
- Analyzing logs for trends over time
Closing the feedback loop
The true value of monitoring in continuous testing comes from using the data to improve your system. This means:
- Setting up actionable alerts that provide enough context to diagnose issues
- Establishing clear response procedures for different types of incidents
- Conducting post-incident reviews to identify root causes
- Feeding insights back into the development process
With tools like Hyperping, you can integrate your monitoring directly with your communication channels (Slack, Teams, etc.) and incident management systems, ensuring the right people get the right information at the right time.
Building a comprehensive continuous testing strategy
Creating an effective continuous testing strategy requires careful planning and a holistic approach. Here's how to build a strategy that works:
1. Define your objectives
What do you want to achieve with your continuous testing strategy? Common objectives include:
- Reducing time to detect and resolve issues
- Improving overall system reliability
- Meeting specific SLAs for availability and performance
- Reducing the number of incidents that impact users
Your objectives should align with broader business goals and be measurable so you can track progress.
2. Assess your current testing approach
Before making changes, understand your starting point by asking questions like:
- What types of testing do we currently perform?
- Where are the gaps in our testing coverage?
- What issues are we missing before production?
- How quickly do we detect and respond to production issues?
This assessment will help you identify priority areas for improvement.
3. Select appropriate tools and technologies
No single tool can address all your testing needs. You'll need to build a toolset that covers:
- Automated testing frameworks for different test types
- CI/CD integration (Organizations are increasingly looking to centralize automation initiatives)
- Test data management
- Monitoring and observability
- Incident management and communication
For monitoring specifically, look for solutions that offer comprehensive coverage while remaining easy to implement. Hyperping provides an all-in-one platform for uptime monitoring, cron job monitoring, and status pages without requiring extensive setup or maintenance.
4. Implement progressively
Don't try to transform your testing approach overnight. Start with high-impact, low-effort improvements and build from there. A phased approach might look like:
- Phase 1: Implement basic uptime monitoring and automated unit tests
- Phase 2: Add integration and functional tests to your CI/CD pipeline
- Phase 3: Implement performance and security testing
- Phase 4: Enhance monitoring with advanced checks and custom metrics
5. Create feedback mechanisms
Continuous testing is only valuable if the insights it generates lead to improvements. Establish processes for:
- Regular review of testing and monitoring data
- Prioritizing issues based on user impact
- Feeding production insights back to development teams
- Continuously improving your testing strategy based on results
6. Document and standardize
Create clear documentation for your testing processes to ensure consistency as your team grows. This should include:
- Test coverage requirements
- Testing environments and procedures
- Monitoring thresholds and alert criteria
- Incident response playbooks (check out these incident communication templates)
- Post-incident review templates
The importance of communication in continuous testing
Even the best testing and monitoring strategy can fall short if you don't communicate effectively about system status and incidents.
Internal communication
When issues arise, team members need clear, timely information to respond effectively. This includes:
- Who's responsible for addressing different types of issues
- What information needs to be communicated during incidents
- How to escalate problems when necessary
- Where to document incidents and resolutions
External communication with status pages
Users and stakeholders also need appropriate updates about system status, especially during incidents. A well-designed status page serves as the central point of truth for system status, both internally and externally. It should:
- Provide real-time updates on system components
- Display planned maintenance windows
- Show incident history and resolution times
- Allow users to subscribe to updates
Hyperping's status page solution integrates directly with its monitoring capabilities, automatically updating when issues are detected and resolved. This eliminates the manual effort often required to keep status pages current and ensures consistent, accurate communication.
Key features to look for in a status page solution include:
- Automated updates based on monitoring alerts
- Custom branding and domains
- Component-level status reporting
- Subscription options for notifications
- Historical uptime reporting
With Hyperping, you can create professional status pages without coding and automatically update them based on your monitoring alerts, saving valuable time during incidents when you need to focus on resolution.
Implementing continuous testing in resource-constrained environments
For startup DevOps and SRE teams with limited resources, implementing comprehensive continuous testing can seem daunting. Here are strategies to maximize impact with minimal resources:
Focus on high-impact areas first
Not all components of your system are equally critical. Identify your most important services—those that directly impact users or revenue—and prioritize testing and monitoring for these areas.
Leverage managed solutions
Building and maintaining testing infrastructure takes time and expertise. Managed solutions like Hyperping provide enterprise-grade capabilities without requiring you to build and maintain complex systems.
Automate strategically
Start by automating tests and checks that:
- Run frequently
- Are prone to human error
- Monitor business-critical functionality
- Provide early warning of developing issues
Build on existing tools
Many teams already use some form of CI/CD tooling. Look for testing and monitoring solutions that integrate with your existing tools to reduce implementation effort and increase adoption.
Common challenges in continuous testing and how to overcome them
Even with the best intentions, teams face several challenges when implementing continuous testing:
- Test maintenance burden — As your system evolves, tests can become brittle and require frequent updates. Focus on testing stable interfaces rather than implementation details to create more resilient tests.
- False positives — Unreliable tests that fail intermittently can undermine confidence in your testing approach. Identify and fix flaky tests quickly, or quarantine them until they can be fixed.
- Slow feedback cycles — Long-running test suites delay feedback. Optimize for speed by running the most critical tests first and parallelizing test execution where possible.
- Testing in production — Many teams are hesitant to test in production. Start with low-risk approaches like synthetic monitoring with tools like Hyperping, then gradually introduce more sophisticated techniques.
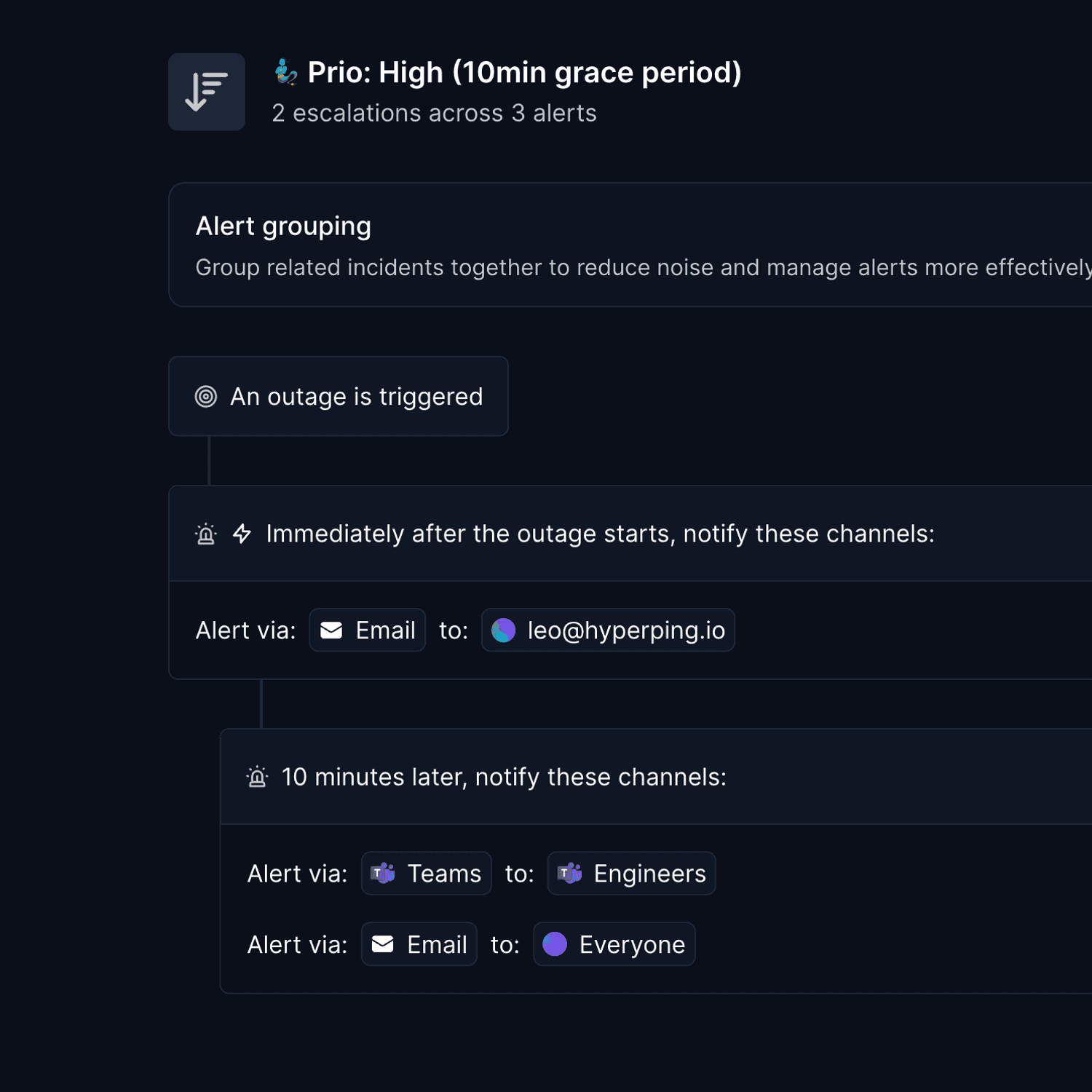
- Alert fatigue — Too many alerts can lead to ignored notifications. Carefully tune monitoring thresholds and alert only on actionable issues that require human intervention. Consider techniques like grouped alerts to reduce noise.
Final thoughts
Continuous testing is a mindset that extends throughout the development lifecycle and into production.
By embracing monitoring as an integral part of your testing strategy, you create a feedback loop that continuously improves your systems' reliability and performance.
The goal is not perfect systems, it's systems that fail less often, recover more quickly, and provide transparency throughout the process.
For teams looking to implement effective continuous testing, tools like Hyperping offer the monitoring foundation you need with minimal setup and maintenance, letting you focus on delivering reliable systems rather than building monitoring infrastructure.
FAQ
What is continuous testing in DevOps? ▼
Continuous testing in DevOps is the process of executing automated tests throughout the entire software delivery pipeline to obtain immediate feedback on business risks associated with the latest build. Unlike traditional testing that happens at specific phases, continuous testing occurs throughout the development lifecycle and extends into production monitoring, providing ongoing verification that systems are performing as expected.
Why is continuous testing important for DevOps teams? ▼
Continuous testing is vital for DevOps teams because it accelerates software delivery by identifying and fixing issues faster, improves software quality with fewer defects reaching production, reduces business risk through early detection of issues, enables continuous feedback on code quality and functionality, and supports DevOps culture by making quality everyone's responsibility. For startups with limited resources, it helps maintain reliability while maximizing efficiency.
What are the key stages of the continuous testing lifecycle? ▼
The continuous testing lifecycle consists of five key stages: 1) Defining your testing strategy based on business goals and available resources, 2) Integrating testing into your CI/CD pipeline with automated tests, 3) Testing in production-like environments to identify real-world issues, 4) Analyzing results and iterating to improve tests and applications, and 5) Extending testing into production through continuous monitoring.
What types of testing should be included in a continuous testing strategy? ▼
A comprehensive continuous testing strategy should include multiple testing types: unit testing to verify individual components, integration testing to ensure components work together correctly, functional testing to validate system requirements, performance testing to evaluate system behavior under various conditions, security testing to identify vulnerabilities, and reliability testing to ensure consistent system availability. Each type serves a specific purpose in ensuring system reliability.
How does monitoring fit into continuous testing? ▼
Monitoring is an essential but often overlooked component of continuous testing. It extends testing into production environments where real user behavior, third-party service interactions, edge cases at scale, and long-running processes can introduce issues impossible to simulate in pre-production. Continuous monitoring acts as an early warning system, alerting teams to problems before they affect users and providing data to improve future development cycles.
What monitoring approaches are most important for continuous testing? ▼
Four key monitoring approaches for continuous testing are: 1) Uptime monitoring to check if services are available from multiple locations, 2) Performance monitoring to track response times, error rates, and resource utilization, 3) Cron job monitoring to ensure background tasks run successfully at expected times, and 4) Log monitoring to analyze system behavior patterns and identify developing issues. Together, these approaches provide comprehensive visibility into production systems.
How can startups implement continuous testing with limited resources? ▼
Startups can implement effective continuous testing with limited resources by focusing on high-impact areas first (prioritizing critical services that directly affect users or revenue), leveraging managed solutions instead of building infrastructure, automating strategically (focusing on tests that run frequently or monitor business-critical functionality), and building on existing tools by choosing testing and monitoring solutions that integrate with current CI/CD systems.
What are common challenges in continuous testing and how can teams overcome them? ▼
Common continuous testing challenges include test maintenance burden (overcome by testing stable interfaces rather than implementation details), false positives (address by quickly fixing flaky tests or quarantining them), slow feedback cycles (optimize by running critical tests first and parallelizing execution), hesitancy about testing in production (start with low-risk approaches like synthetic monitoring), and alert fatigue (tune thresholds carefully and implement grouped alerts to reduce noise).
How important are status pages for continuous testing? ▼
Status pages are critical for the communication aspect of continuous testing. They serve as a central point of truth for system status both internally and externally, providing real-time updates on system components, displaying planned maintenance windows, showing incident history, and allowing users to subscribe to updates. Status pages that automatically update based on monitoring alerts ensure consistent, accurate communication during incidents.
How should teams build a comprehensive continuous testing strategy? ▼
To build an effective continuous testing strategy, teams should: 1) Define clear, measurable objectives aligned with business goals, 2) Assess the current testing approach to identify gaps, 3) Select appropriate tools covering automated testing, CI/CD integration, monitoring, and incident management, 4) Implement changes progressively rather than all at once, 5) Create feedback mechanisms to drive continuous improvement, and 6) Document and standardize processes to ensure consistency as the team grows.