
System outages cost businesses an average of $5,600 per minute, according to Gartner. That's over $300,000 per hour of downtime.
But beyond the financial impact, downtime destroys customer trust, damages your reputation, and creates a backlog of urgent work for your already busy technical teams.
The key to minimizing downtime? A robust DevOps alert management system that notifies you of issues before they become full-blown disasters.
In this guide, we'll explore everything you need to know about DevOps alert management, including best practices, common challenges, and practical steps to implement an effective system for your organization.
TL;DR:
- DevOps alert management prevents $300K+/hour downtime costs
- Shifts teams from reactive firefighting to proactive monitoring
- Requires clear thresholds, prioritization, and actionable alerts
- Alert fatigue is the #1 challenge teams face
- Modern AI tools can reduce alert noise by 70%+
What is DevOps alert management?
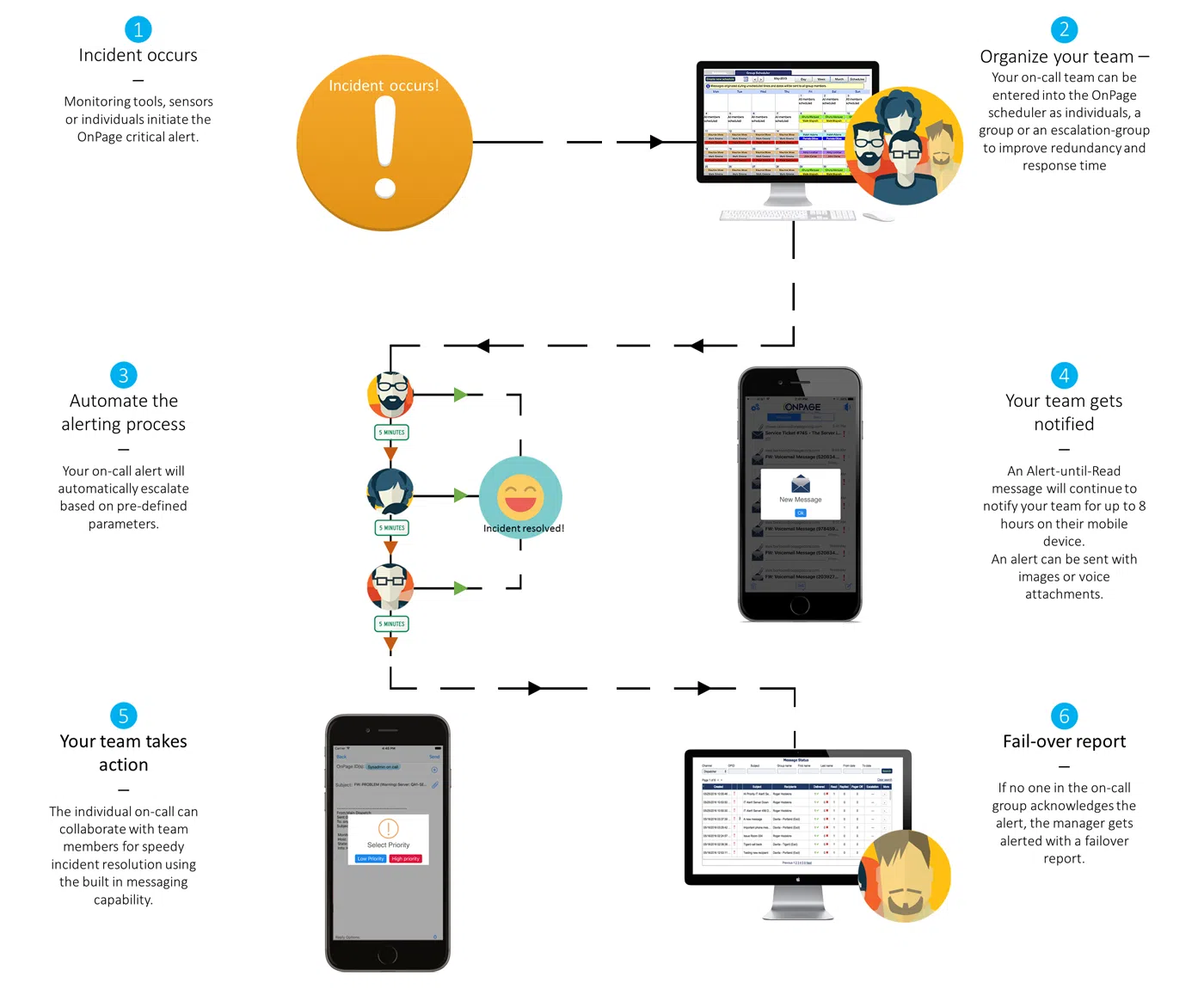
Definition: DevOps alert management is the systematic approach to monitoring, organizing, prioritizing, and responding to system notifications in real-time.
DevOps alert management is the systematic approach to monitoring systems in real-time and generating alerts when predefined thresholds are breached. It's the practice of setting up, organizing, prioritizing, and responding to notifications about potential issues in your technical infrastructure.
An effective alert management system doesn't just notify you when something breaks—it provides actionable information that helps you:
- Detect and address issues before they escalate
- Minimize system downtime and improve reliability
- Enable collaboration between development and operations teams
- Maintain service level agreements (SLAs)
- Build customer trust through reliable service
Without proper alert management, teams often find themselves in a reactive firefighting mode, responding to issues only after users are affected. This approach leads to longer resolution times, increased stress, and diminished service quality.
Effective alert management, on the other hand, shifts the paradigm from reactive to proactive, allowing teams to identify and address potential problems before they impact users.
Why is alert management critical for DevOps teams?
For DevOps and SRE teams, alert management isn't just a nice-to-have—it's essential for maintaining system reliability and team sanity.
Increased system complexity
Modern applications are increasingly complex, spanning multiple services, cloud platforms, and infrastructure components. This complexity makes it nearly impossible for teams to manually monitor everything without the help of automated alerting systems.
Customer expectations
Today's users expect near-perfect uptime. When services go down, they don't just wait patiently—they switch to competitors, complain on social media, and reconsider their loyalty to your brand.
Resource optimization
Efficient alert management helps teams focus their attention on genuine issues rather than constantly checking system health. This optimization allows for better use of limited human resources.
Improved collaboration
Well-designed alerts facilitate communication between development and operations teams, creating a shared understanding of system health and fostering collaborative problem-solving.
Key components of effective alert management
To build a reliable alert management system, you need to focus on these critical components:
1. Clear alert thresholds
Effective alerting starts with defining appropriate thresholds—the boundaries that, when crossed, trigger notifications. These thresholds should be:
- Tailored to specific applications and systems
- Based on historical performance data
- Regularly reviewed and adjusted to reflect changing workloads
- Aligned with service level objectives (SLOs)
For example, rather than setting a generic CPU usage alert at 80% for all services, you might set different thresholds based on each service's typical performance patterns and importance.
| Alert type | Use case | Priority | Response time | Example |
|---|---|---|---|---|
| Performance | Slow response times | Medium | 15 minutes | API latency > 1s |
| Availability | Service downtime | Critical | Immediate | HTTP 5xx errors > 10/min |
| Resource | Capacity planning | Low | 1 hour | CPU usage > 70% for 5 min |
| Security | Unauthorized access | High | 5 minutes | Failed logins > 20/min |
| Business | Transaction failures | Critical | Immediate | Payment failures > 5% |
2. Alert prioritization
Not all alerts are created equal. A minor performance degradation in a non-critical system doesn't warrant the same response as a payment processing failure.
Effective alert prioritization includes:
- Categorizing alerts by severity (e.g., low, medium, high priority)
- Establishing clear escalation policies for critical alerts
- Considering business impact when determining priority
- Creating different notification channels based on severity
| Severity level | Response time | Examples | Notification method |
|---|---|---|---|
| Low | Next business day | Disk usage at 60%, Non-critical service warnings | Email, Dashboard |
| Medium | 1-4 hours | Performance degradation, Non-critical errors | Team channel, Email |
| High | 30 minutes | Service partial outage, Critical component warnings | Phone call, SMS, Slack |
| Critical | Immediate | Complete service outage, Security breach, Data loss | All channels, Escalation |
3. Actionable alerts
The most useful alerts provide sufficient context for responders to take immediate action. An alert that simply states "API Error" forces the responder to spend valuable time investigating the issue.
Actionable alerts include:
- Specific error messages
- Relevant logs and metrics
- Information about recent changes that might have contributed to the issue
- Potential remediation steps or runbooks
- Historical context about similar incidents
4. Automated responses
Not every alert requires human intervention. For known issues with clear resolution paths, automating the response can save time and reduce the burden on your team.
Examples of automated responses include:
- Scaling resources when utilization reaches critical levels
- Restarting services that have entered a known bad state
- Rolling back recent deployments that are causing issues
- Running diagnostic scripts to gather more information
5. Integration with collaboration tools
Alerts are most effective when they reach the right people through channels they already use. Integrating your alert system with collaboration tools ensures that notifications aren't missed.
Key integrations might include:
- Chat platforms like Slack or Microsoft Teams
- Incident management platforms like PagerDuty
- Ticketing systems like Jira
- Email and SMS for critical issues
6. Feedback loops
Alert configurations should evolve based on real-world experience. After each incident, teams should review the effectiveness of related alerts and make adjustments as needed.
Effective feedback loops might include:
- Post-incident reviews that evaluate alert effectiveness
- Regular analysis of alert noise and false positives
- Continuous refinement of thresholds based on system changes
- Documentation of alert patterns and their correlation to actual issues
Best practices for DevOps alert management
Now that we understand the key components, let's explore some best practices for implementing effective alert management:
Define what's truly alertable
Not everything that can be measured should trigger an alert. Reserve alerts for conditions that:
- Are actionable (someone needs to do something in response)
- Require urgent attention (can't wait until the next business day)
- Impact users or critical business functions
For less urgent issues, consider using alternative notification methods like daily reports or dashboards.
Implement the "three W's" for every alert
Each alert should clearly communicate:
| Question | Description | Example |
|---|---|---|
| What | Specific issue | "Payment API response time >2s" |
| Why | Business impact | "Affects checkout completion rate" |
| Who | Responsible team | "Payment team on-call" |
This clarity helps responders quickly understand the situation and take appropriate action.
Use tiered alerting approaches
Instead of having a single threshold that triggers a high-priority alert, consider implementing multiple thresholds with escalating severity:
- Warning threshold: Generates a low-priority notification in a monitoring dashboard
- Minor alert threshold: Sends a notification to a team channel during business hours
- Major alert threshold: Pages on-call engineers immediately, regardless of time
This approach helps prevent alert fatigue while ensuring critical issues receive proper attention.
Adopt "alerts as code"
Managing alert configurations through version-controlled code repositories offers several advantages:
- Consistent alert definitions across environments
- Change history and accountability
- Easier testing and validation
- Simplified deployment through CI/CD pipelines
Tools like Terraform and Prometheus's Alertmanager support this approach, allowing teams to define alert rules in version-controlled configuration files.
Regularly test your alerting system
Your alerting system is only effective if it works when needed. Regular testing helps identify gaps before they become problems:
- Simulate failures to verify that alerts trigger as expected
- Test escalation paths to ensure notifications reach the right people
- Verify that runbooks and documentation are up to date
- Practice incident response to improve team coordination
Implement alert correlation
In complex systems, a single issue can trigger multiple related alerts, creating unnecessary noise. Alert correlation groups related notifications to provide a clearer picture of the underlying problem.
For example, if a database becomes unavailable, you might receive alerts for:
- Database connectivity failures
- API errors that depend on the database
- Increased latency in multiple services
- Failed background jobs
Instead of generating separate notifications for each symptom, an intelligent alerting system would identify the common cause and create a single, comprehensive alert.
Addressing alert fatigue: The DevOps team's nemesis
Alert fatigue occurs when teams receive so many notifications that they become desensitized, potentially missing critical issues amid the noise. This phenomenon is one of the biggest challenges in alert management.
Signs of alert fatigue
Your team might be experiencing alert fatigue if:
- Engineers regularly ignore or dismiss alerts without investigation
- Response times to genuine issues are increasing
- Team members express frustration about "noisy" monitoring
- On-call rotations are dreaded due to constant interruptions
- Post-incident reviews reveal that warning signs were present but missed
| Symptom | Solution strategy |
|---|---|
| Ignored alerts | Reduce alert volume, improve alert quality |
| Increased response times | Implement better prioritization, automate responses |
| Team frustration | Rotate responsibilities, provide better context |
| Dreaded on-call | Balance workload, reduce false positives |
| Missed warning signs | Implement alert correlation, improve visibility |
Strategies to combat alert fatigue
Industry Benchmark: Average DevOps team receives 2,000+ alerts/week, but only 3% require immediate action
1. Reduce alert noise
Start by eliminating redundant or low-value alerts:
- Audit existing alerts and remove those that haven't led to meaningful action
- Combine related alerts to reduce duplication
- Increase thresholds for non-critical metrics
- Implement "flapping detection" to prevent alerts that rapidly activate and resolve
2. Improve alert quality
Focus on making each alert more valuable:
- Add context to help responders quickly understand the issue
- Include links to relevant documentation or runbooks
- Provide historical data to show patterns and trends
- Suggest potential remediation steps based on past incidents
3. Implement intelligent alerting
Use advanced techniques to filter and prioritize alerts:
- Machine learning algorithms can identify unusual patterns that warrant attention
- Anomaly detection can focus on deviations from normal behavior rather than static thresholds
- Correlation engines can group related alerts to reduce noise
- Time-based rules can adjust sensitivity based on business hours or known busy periods
4. Rotate responsibilities
Spread the alert burden across your team:
- Implement fair on-call rotations with clear handoff procedures
- Create separate rotations for different types of alerts
- Establish "quiet hours" for non-critical notifications
- Ensure team members have adequate recovery time after high-stress incidents
Tools for effective DevOps alert management
A robust alert management strategy requires the right tools. Here are some popular options to consider:
| Tool | Type | Key features | Best for | Pricing model |
|---|---|---|---|---|
| Hyperping | Uptime monitoring & status pages | Uptime monitoring, SSL checks, cron job monitoring, automated status pages | Teams needing reliable monitoring with status page integration | Subscription |
| Prometheus | Open-source monitoring | Powerful query language, alerting rules, time series database | Teams with Kubernetes/cloud-native infrastructure | Free/Open-source |
| Datadog | Cloud monitoring | Full-stack observability, AI-powered analytics, 600+ integrations | Enterprise teams needing comprehensive monitoring | Usage-based |
| PagerDuty | Incident management | Alert routing, on-call scheduling, escalation policies | Teams needing advanced incident response workflows | Per-user |
| OpsGenie | Alert management | Alert consolidation, on-call management, team collaboration | Teams using Atlassian ecosystem | Per-user |
| BigPanda | Alert correlation | AI-driven correlation, root cause analysis, workflow automation | Large enterprises with complex infrastructure | Enterprise |
| New Relic | APM | Application performance monitoring, distributed tracing, real user monitoring | Development teams focusing on application performance | Usage-based |
| Grafana | Visualization | Custom dashboards, alert rules, multiple data sources | Teams wanting flexible visualization options | Free/Open-source |
| VictorOps | Incident response | Real-time collaboration, timeline tracking, post-incident reviews | Teams prioritizing incident collaboration | Per-user |
| Statuspage | Status communication | Public status pages, incident updates, subscriber notifications | Customer-facing teams | Subscription |
Source: OnPage
Quick reference card
| Guideline | Recommendation |
|---|---|
| Alert frequency | Max 5-10 actionable alerts per day per team |
| False positive rate | Target < 5% of total alerts |
| Response time - Critical | < 5 minutes |
| Response time - High | < 30 minutes |
| Response time - Medium | < 4 hours |
| On-call rotation | 1 week max, with 2+ week breaks |
| Team size for 24/7 coverage | Minimum 6-8 engineers |
| Alert review frequency | Weekly for active tuning, monthly for comprehensive review |
| Documentation update | Within 24 hours of incident resolution |
| Runbook coverage | 80% of recurring alerts should have runbooks |
Step-by-step guide to implementing effective alert management
Ready to improve your alert management system? Here's a practical implementation plan:
1. Assess your current state
Begin by evaluating your existing alerting practices:
- Document all current alert configurations across systems
- Analyze alert volume, frequency, and actionability
- Review recent incidents to identify gaps in alerting coverage
- Gather feedback from team members about alert effectiveness
- Identify pain points in the current process
This assessment will help you understand what's working, what's not, and where to focus your improvement efforts.
2. Define your alerting philosophy
Create clear guidelines for what should trigger alerts in your organization:
- Establish criteria for alert severity levels
- Define response expectations for each severity level
- Determine which metrics are truly alertable
- Set standards for alert content and format
- Document escalation paths for different types of alerts
Getting team consensus on these fundamentals will ensure consistency in your alerting approach.
3. Select and configure your tooling
Based on your assessment and alerting philosophy, choose appropriate tools:
- Implement monitoring platforms that support your alerting needs
- Configure incident management systems for notification routing
- Set up status pages for external communication
- Establish integrations between your various tools
- Create dashboards for visualizing system health
For example, you might use Hyperping to monitor your critical services and automatically update your status page when issues are detected, while routing alerts to team members through Slack or PagerDuty.
4. Define and implement alert rules
With your tooling in place, create specific alert definitions:
- Start with critical services and high-impact failure modes
- Define appropriate thresholds based on historical data
- Implement "alerts as code" for version control
- Create runbooks for common alert scenarios
- Test rules thoroughly before deploying to production
Remember to focus on quality over quantity—it's better to have a few reliable, actionable alerts than dozens of noisy ones.
5. Train your team
Ensure everyone understands the new alerting system:
- Conduct workshops on alert response procedures
- Review runbooks and documentation together
- Practice handling different types of alerts
- Clarify roles and responsibilities for incident response
- Establish communication protocols for major incidents
Well-trained teams respond more effectively to alerts, reducing resolution time and minimizing impact.
6. Implement continuous improvement
Your alert management system should evolve over time:
- Conduct regular reviews of alert effectiveness
- Analyze patterns in false positives and missed issues
- Update thresholds based on changing system behavior
- Refine runbooks based on incident learnings
- Incorporate feedback from team members
Schedule quarterly reviews to assess overall system health and make needed adjustments.
Emerging trends in DevOps alert management
The field of alert management is continuously evolving. Here are some trends to watch:
AI and machine learning
Artificial intelligence is transforming alert management by:
| AI feature | Traditional approach | AI-enhanced approach | Potential impact |
|---|---|---|---|
| Anomaly detection | Static thresholds | Dynamic pattern recognition | 70% fewer false positives |
| Alert correlation | Manual rule creation | Automatic relationship discovery | 85% noise reduction |
| Root cause analysis | Manual investigation | Automated dependency mapping | 50% faster MTTR |
| Predictive alerts | Reactive monitoring | Proactive failure prediction | 30% reduction in incidents |
| Alert prioritization | Fixed severity levels | Dynamic impact assessment | 40% better resource allocation |
| Remediation suggestions | Static runbooks | Context-aware recommendations | 60% faster resolution |
Context-aware alerting
Modern alert systems are becoming more sophisticated in understanding context:
- Time-aware alerts that adjust sensitivity based on business hours
- Location-aware alerts that consider geographic dependencies
- User-impact alerts that prioritize based on affected customers
- Business-aligned alerts that consider revenue or SLA impact
- Change-aware alerts that correlate with recent deployments
This contextual awareness helps teams focus on what matters most in any given situation.
Observability beyond monitoring
Traditional monitoring focuses on predefined metrics and thresholds. Observability expands this approach by:
- Incorporating logs, metrics, and traces for comprehensive visibility
- Supporting exploratory analysis of system behavior
- Enabling teams to answer unanticipated questions about system state
- Providing deeper context for troubleshooting
- Facilitating root cause analysis
As teams adopt observability practices, their alerting approaches will evolve to leverage these richer data sources.
SLO-based alerting
Expert Insight: "SLO-based alerting reduces alert volume by 85% while improving incident detection" — Google SRE Handbook.
Rather than alerting on individual metrics, more teams are shifting toward Service Level Objective (SLO) based alerting:
- Define acceptable service performance in terms of user experience
- Alert when error budgets are at risk of being exhausted
- Focus on customer-impacting issues rather than internal metrics
- Reduce alert noise by consolidating multiple thresholds into a single SLO
- Align technical monitoring with business priorities
This approach helps teams maintain focus on what truly matters—the end-user experience.
Related terms glossary
| Term | definition |
|---|---|
| Alert correlation | The process of grouping related alerts to identify root causes and reduce notification noise |
| Alert threshold | The predefined value or condition that triggers an alert when exceeded |
| Anomaly detection | Identifying unusual patterns or behaviors that deviate from normal system operation |
| Error budget | The acceptable amount of downtime or errors allowed within an SLO period |
| Escalation policy | Rules defining how alerts are routed to team members based on severity and time |
| False positive | An alert triggered when no actual problem exists |
| Flapping detection | Identifying alerts that repeatedly trigger and resolve in quick succession |
| Incident management | The process of responding to and resolving service disruptions |
| MTTD (Mean Time to Detect) | Average time between issue occurrence and detection |
| MTTR (Mean Time to Resolve) | Average time between issue detection and resolution |
| On-call rotation | Schedule defining which team members are responsible for responding to alerts |
| Runbook | Step-by-step documentation for responding to specific alerts or incidents |
| Service Level Agreement (SLA) | Contractual commitment about service availability and performance |
| Service Level Indicator (SLI) | Metric measuring a specific aspect of service performance |
| Service Level Objective (SLO) | Internal target for service reliability based on SLIs |
Final thoughts
Effective DevOps alert management is a balancing act.
The key is to focus on quality over quantity — each alert should be actionable, meaningful, and clear.
By implementing the best practices outlined in this guide, you can create an alert system that enhances your team's effectiveness rather than hindering it.
Tools like Hyperping can play a crucial role in this ecosystem, providing reliable uptime monitoring and automated status pages that integrate seamlessly with your broader alert management approach.
By monitoring critical endpoints, verifying SSL certificates, and ensuring your cron jobs are running properly, Hyperping helps you detect issues before they impact your users — the ultimate goal of any alert management system.
Related reading
- Escalation policies guide — build a framework for routing alerts
- Best on-call scheduling tools — compare on-call management platforms
- MTTR guide — measure and improve your incident response time
- Incident post-mortem guide — learn from incidents to prevent recurrence
- SLA vs SLO vs SLI — understand the reliability metrics that matter
- On-call hub — all our on-call and alerting resources
FAQ
What is DevOps alert management? ▼
DevOps alert management is a systematic approach to monitoring systems in real-time and generating notifications when predefined thresholds are breached. It involves setting up, organizing, prioritizing, and responding to alerts about potential issues in technical infrastructure to prevent system downtime and maintain service reliability.
How much does system downtime cost businesses? ▼
According to Gartner, system outages cost businesses an average of $5,600 per minute, which amounts to over $300,000 per hour of downtime. This doesn't include indirect costs like damaged customer trust and reputation.
What are the key components of effective alert management? ▼
The key components include clear alert thresholds, alert prioritization systems, actionable alerts with context, automated responses, integration with collaboration tools, and established feedback loops for continuous improvement.
How can teams prevent alert fatigue in DevOps? ▼
Teams can prevent alert fatigue by reducing alert noise through alert correlation, implementing intelligent alerting systems, improving alert quality with proper context, rotating responsibilities among team members, and regularly auditing and updating alert thresholds.
What tools are essential for DevOps alert management? ▼
Essential tools include monitoring platforms like Hyperping, Prometheus, and Datadog; incident management tools like PagerDuty and OpsGenie; alert correlation tools like BigPanda; and status page providers for external communication.
What are the best practices for implementing alert management? ▼
Best practices include defining truly alertable conditions, implementing the 'three W's' (What, Why, Who) for every alert, using tiered alerting approaches, adopting alerts as code, regularly testing the alerting system, and implementing alert correlation.
How does AI impact DevOps alert management? ▼
AI is transforming alert management through anomaly detection based on complex patterns, predictive failure analysis, intelligent alert correlation to reduce noise, automated remediation suggestions based on historical data, and smart alert prioritization based on impact assessment.
What is SLO-based alerting in DevOps? ▼
SLO-based alerting is an approach that focuses on Service Level Objectives rather than individual metrics. It alerts teams when error budgets are at risk, emphasizes customer-impacting issues, reduces alert noise, and aligns technical monitoring with business priorities.



