
When systems go down, every minute counts. You need more than just quick fixes.
You need a solid system to spot problems early, take action fast, and learn from each incident to keep your users happy. That's what incident management is.
In this guide, we'll walk through everything you need to know about incident management, from basic concepts to advanced strategies used by top DevOps teams.
What is incident management?
Incident management is the process of responding to and resolving unplanned interruptions or reductions in the quality of IT services.
Simply put, it's how your team handles things when they break.
For example, let's say your payment system stops working at 2 AM. Good incident management means:
- Your monitoring system alerts the right people
- Your team knows exactly who should respond
- You have a clear process to investigate and fix the issue
- You keep customers informed through your status page
- You document everything to prevent it from happening again
Without proper incident management, small issues can snowball into major problems.
It's the difference between a 5-minute blip and a 5-hour outage that costs you customers and money.
Why incident management matters
Downtime is expensive
Every minute of downtime can cost thousands in lost revenue. But the real cost goes beyond money:
- Damaged customer trust — Once broken, trust takes months to rebuild. Customers remember bad experiences longer than good ones.
- Lost productivity — Your team stops building and starts firefighting. Features get delayed. Growth slows down.
- Stressed team members — Late night alerts and pressure to fix issues quickly lead to burnout. Tired teams make more mistakes.
- Missed SLA targets — Breaking promises to customers puts contracts at risk. Enterprise clients may look elsewhere.
The hidden costs add up
When systems go down, the visible costs are just the tip of the iceberg. Here's what happens behind the scenes:
- Customer support gets swamped — Support tickets spike 5-10x, overwhelming teams and frustrating customers.
- Sales pipeline takes a hit — Deals pause or cancel as prospects lose confidence.
- Team morale crumbles — It drops from constant firefighting and late-night fixes.
- Technical debt snowballs — It grows as quick fixes create new problems
- Brand Trust Erodes — Through negative reviews and social media
The good news? You can prevent most problems with the right monitoring tools and clear communication channels. It's about staying ahead, not playing catch-up.
Good incident management builds trust
When you handle incidents well, everyone wins.
Your customers stay confident in your service because they see you're on top of issues.
Your teams feel prepared and capable with clear processes to follow.
Stakeholders understand what's happening through transparent communication.
And with automated monitoring, recovery becomes faster and more predictable.
Prevention is better than cure
Smart monitoring helps you catch issues before customers notice them.
You'll track patterns that prevent future incidents and spend more time building instead of fixing.
And you'll sleep better knowing your systems are watched 24/7.
Great teams know that fixing issues quickly is good, but spotting them early is even better.
That's why proper monitoring and status pages are essential tools for modern teams.
Common mistakes in incident management
1. No clear process
Many teams handle each incident differently, creating chaos when problems arise. This leads to:
- Confusion about who does what — Teams waste precious time figuring out roles and responsibilities during critical moments. Should DevOps handle this? Is it an SRE issue? The uncertainty slows everything down.
- Missed steps — Without a checklist, important actions get forgotten. Like forgetting to check logs before restarting services, or not documenting the fix for future reference.
- Slower resolution times — When everyone's scrambling to figure out the process, incidents take longer to resolve. A 15-minute outage becomes a 2-hour nightmare.
- Repeated mistakes — Without a standard process, teams keep making the same errors. They'll restart services without checking dependencies, or push fixes without proper testing.
2. Poor communication
Communication breaks down when teams are under pressure. Problems multiply when:
- Updates aren't shared regularly.
- The wrong people are notified.
- Messages are unclear or technical.
- Customers are left in the dark.
3. Rushing to fix without understanding
The pressure to restore service often leads to hasty decisions.
When something breaks, it's tempting to just restart services without understanding why they failed.
Not finding root causes means the same issues keep happening. That memory leak will keep crashing your service until you find its source.
And then there's the trap of fixing symptoms instead of problems. Adding more servers when the real issue is inefficient code is like buying a bigger house because you can't find things — it just spreads the mess around.
4. Incomplete documentation
Poor documentation cripples incident response:
- Lost knowledge
- Harder training
- Slower future responses
- Missed improvement opportunities
Good documentation isn't just nice to have — it's how reliable teams stay reliable.
Think of documentation as your team's memory. Without it, you're starting from scratch every time.
The 5 core components of incident management
Every tech team faces incidents. But how you handle them makes all the difference. Let's break down the essential pieces of effective incident management.
1. Detecting issues early
Catching problems fast means less downtime and happier users.
- Use monitoring tools to catch problems early
- Set up alerts for critical systems
- Watch for unusual patterns or behavior
2. Responding quickly and effectively
Time matters when things break. Every minute of downtime can hurt your reputation and bottom line.
- Have an on-call rotation ready
- Follow clear escalation procedures
- Communicate with affected users
3. Fixing the immediate problem
When your systems go down, your first priority should be getting back online fast.
- Identify the root cause
- Apply temporary fixes if needed
- Get systems back online quickly
4. Learning from what happened
Every incident is a chance to make your systems better.
- Run post-mortems after major incidents
- Document what went wrong and why
- Share knowledge across the team
5. Prevent similar issues
Each incident is a chance to make your systems more reliable. Take time to implement preventive measures.
- Update monitoring based on lessons learned
- Improve system resilience
- Add safeguards against common failures
Incident Management Best Practices
1. Create clear roles and responsibilities
A well-structured incident response team helps everyone know exactly what they should be doing instead of stepping on each other's toes.
Define specific roles for:
- Incident commander — leads response and makes final calls
- Communications lead — handles updates to stakeholders
- Technical lead — directs troubleshooting efforts
- Operations support — executes required changes
- Documentation owner — records timeline and actions
This division of responsibilities prevents the common problem of everyone trying to do everything — which usually leads to nothing getting done properly.
Tips for role clarity:
- Document each role's scope and limits
- Have backups for key positions
- Rotate roles during drills
- Keep contact info updated
2. Establish incident classification system
Define clear severity levels to help your team respond appropriately and efficiently to incidents. This prevents both over and under-reactions to problems.
Define severity levels based on:
- Business impact (revenue loss, reputation)
- Number of affected users
- System availability
- Data integrity risks
Review and adjust your classification system quarterly based on real incidents and team feedback.
This helps keep it relevant and effective.
3. Document everything thoroughly
Create a detailed timeline that captures when the incident started and how it evolved.
Record every action your team took and whether it helped solve the problem.
Keep logs of all internal and customer communications during the incident.
Once resolved, write down what caused the issue and the exact steps that fixed it.
Most importantly, document the key lessons so your team can prevent similar problems in the future.
This thorough documentation helps you learn from incidents and makes your systems more reliable over time. It also helps new team members understand past issues and their solutions.
4. Leverage smart automation
Automate every step of your incident response workflow.
Implement automation for:
- System health checks
- Alert routing
- Initial diagnostics
- Standard recovery steps
- Status updates
- Metric collection
This automation-first approach saves precious time when incidents occur, reduces human error, and helps your team focus on solving complex problems instead of repetitive tasks.
5. Conduct regular practice sessions
Here are a few types of practice sessions you could try:
- Table-top exercises — Get the team together to walk through scenarios on paper. Talk about "What would you do if X happened?" This builds muscle memory without the stress of real incidents.
- Live simulations — Break things on purpose in a controlled way. Pull the plug on servers, trigger errors, or cut off database access. See how your team reacts in real-time.
- Recovery testing — Make sure your backup plans actually work. Can you restore from backups? Do your failover systems kick in properly? Test it regularly.
- Communication checks — Practice how you'll talk to each other during incidents. Test your paging systems, chat tools, and escalation paths. Make sure everyone knows their role.
- Cross-team scenarios — Don't just test in silos. Run drills that involve multiple teams like engineering, support, and comms. Real incidents rarely affect just one team.
6. Master crisis communication
Clear and concise messages help everyone understand what's happening.
Technical jargon only creates confusion, so keep it simple.
Regular updates show you're on top of things, even if there's no major news to share.
When sharing updates, explain how users are affected and when you expect things to be fixed.
It's okay to say "we're not sure yet" — honesty builds trust.
And after fixing the issue, follow up to explain what happened and how you'll prevent it next time.
Channels to consider:
- Status page
- Email updates
- Social media
- Internal chat
- Customer support
7. Develop comprehensive playbooks
Your playbooks should be living documents that guide teams through every phase of incident response.
Start with clear initial assessment steps so anyone can quickly evaluate the situation.
Include step-by-step diagnostic procedures to identify root causes efficiently.
Map out proven recovery processes that restore services fast.
Define clear escalation paths so everyone knows who to contact and when.
Add ready-to-use communication templates to keep stakeholders informed consistently.
Don't forget post-incident tasks like documentation and follow-ups. These playbooks only work if they stay current, so review and update them often. Write them in simple language that's easy to follow, even under pressure.
Make sure teams can access these guides from anywhere — you never know where you'll be when incidents strike. And regularly test these procedures to ensure they actually work in real situations.
8. Implement thorough monitoring
Effective monitoring is crucial for maintaining reliable systems.
Without proper visibility, issues can spiral out of control before you notice them.
Many teams rely on basic checks or wait for customer complaints.
But this reactive approach leads to longer downtimes, frustrated users, and damaged trust. You need a proactive monitoring strategy.
The good news is that modern monitoring tools make it easier than ever to track system health.
Start by monitoring these key areas:
- Infrastructure health
- Application performance
- User experience
- Business metrics
- Security indicators
- Dependencies
9. Build a learning culture
Make learning part of your culture by creating shared repositories of knowledge.
Write clear best practice guides that teams can follow.
Develop training materials to help new team members get up to speed.
Build comprehensive knowledge bases that capture institutional wisdom.
Remember: every incident is a chance to learn and grow stronger as a team. The key is creating an environment where people feel safe sharing mistakes and lessons learned.
10. Prioritize proactive prevention
Rushing to fix problems after they happen is exhausting. And expensive. And terrible for your mental health.
You can prevent most issues before they blow up in your face though.
Start with the basics:
- Run regular system checks (like a mechanic inspecting a car)
- Test how your systems perform under pressure
- Try breaking things on purpose (chaos engineering)
- Look for security holes before attackers do
- Plan ahead for growth
- Make sure your backups actually work
Build stronger systems by:
- Getting fresh eyes on your architecture
- Testing what happens when things fail
- Seeing how much load your system can take
- Making sure you can recover from disasters
- Actually practicing your emergency plans
Think of it like health — prevention is way better than cure. Your future self (and your sleep schedule) will thank you.
Essential incident management tools
When incidents strike, having the right tools makes all the difference between quick resolution and extended downtime.
Here's the essential tools that help teams stay on top of their systems.
Monitoring tools

Monitoring tools act as your system's early warning system. They help catch issues before they impact users.
Hyperping is one such tool and provides:
- Browser checks that act like real users
- Cron job monitoring to catch failed tasks
- SSL monitoring to prevent certificate issues
- Custom alerts so the right people know right away
See how Hyperping compares to other monitoring solutions to find the best fit for your needs.
No more manual checks or unreliable scripts. Just peace of mind knowing your systems are watched.
Communication tools
Everyone knows about Slack, Microsoft Teams, and other communication tools.
But what's really the best one?
Here's how to pick the right communication tool:
Consider your team size
Small teams can get by with simple chat apps, but larger teams need structured channels and access controls.
Look at integration needs
Your communication tools must work smoothly with your existing stack.
Check alert handling
Good alert routing prevents chaos during incidents.
Think about accessibility
Your team needs tools they can use anywhere, anytime. This means solid mobile apps, interfaces that work under stress, and features that support teams across different time zones.
Documentation tools
The tool matters less than building good documentation habits.
As we have seen previously, it's important to keep your documentation fresh and useful. Review it after each incident, add new learnings, and remove outdated information. Make sure it's easy to find when you need it most.
With all of that in mind, choose the one that your team will use most — Confluence, GitBook, Notion, Google Docs, or something else.
Status page tools
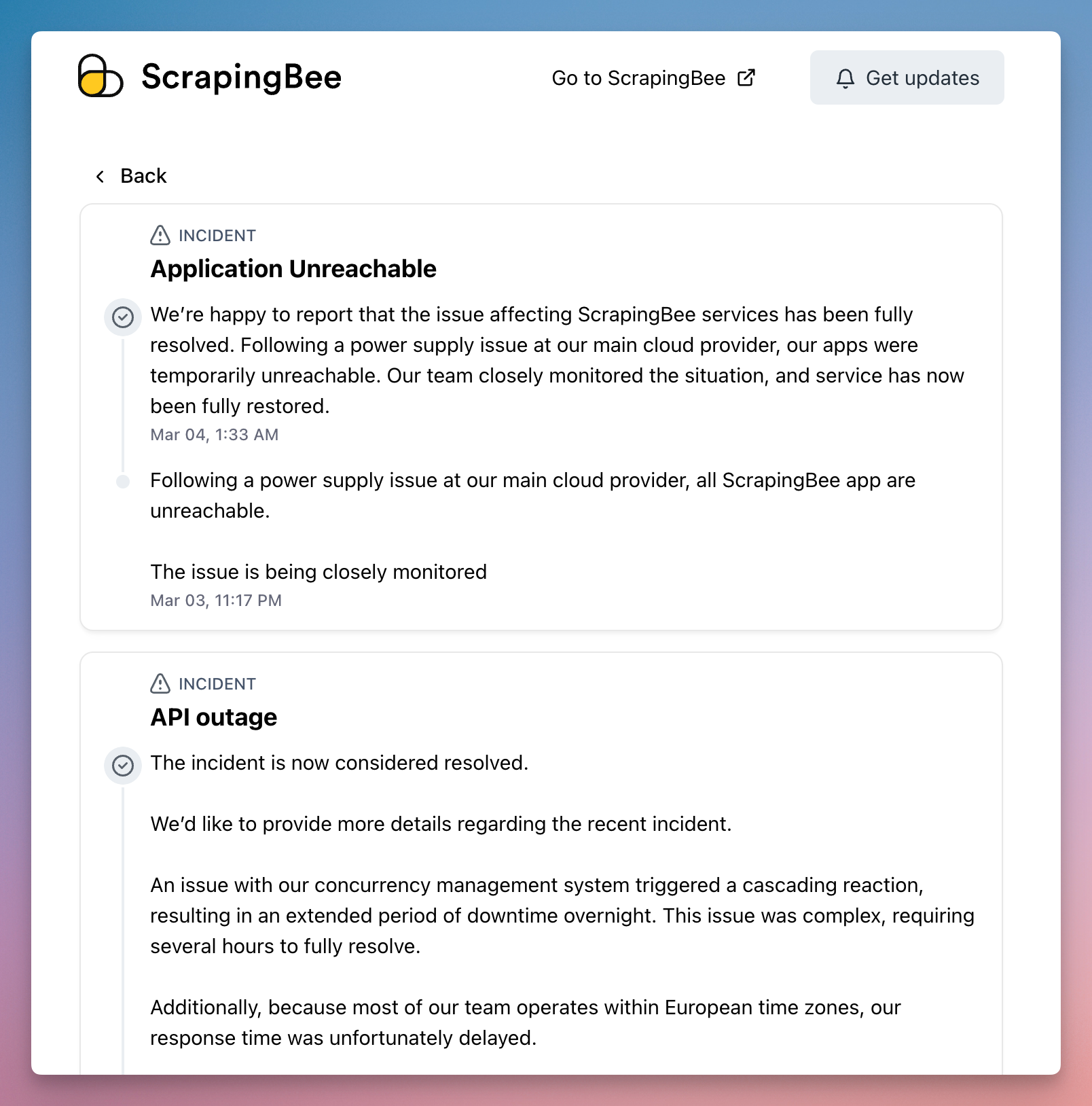
A status page helps you tell users what's happening right away, share updates as you fix issues, warn about planned maintenance, and build trust through transparency.
Building your own status page sounds easy at first. But it quickly becomes messy. Updates are manual and time-consuming. Notifications break or miss people. Maintenance becomes a burden. And features stay basic and limited.
Users today expect more. They want real-time updates when systems are down. They want a clear timeline of what's being fixed. They want multiple ways to get notifications. And they expect professional, reliable communication.
Hyperping gives you all this out of the box. Check out our customer showcase to see how leading companies use Hyperping status pages to keep their users informed.
Conclusion
Good incident management isn't just about fixing problems — it's about building reliable systems and trusted relationships with users.
By following these practices and using the right tools, you can:
- Respond faster
- Recover better
- Learn more
- Prevent future issues
Remember: incidents will happen. What matters is how well you handle them.
Want to improve your incident management? Start with good monitoring. Check out Hyperping's uptime monitoring and status page platform to catch issues before your users do.
Frequently Asked Questions
What are the 4 R's of incident management?
- Response
- Resolution
- Recovery
- Review
What makes a good incident manager?
A good incident manager demonstrates:
- Calm under pressure
- Clear communication
- Quick decision-making
- Learning mindset
What's the difference between incident and problem management?
Incident management:
- Focuses on immediate restoration
- Handles specific events
- Aims for quick resolution
- Reactive in nature
Problem management:
- Looks at underlying causes
- Handles patterns and trends
- Aims for long-term solutions
- Proactive in nature



