
Monitoring systems have become absolutely critical for modern businesses, and understanding the fundamentals of application monitoring is key to success.
But when it comes to serverless monitoring, the game gets even trickier. Serverless architectures, while offering incredible flexibility and cost advantages, present unique monitoring challenges that traditional approaches simply can't handle.
This guide will walk you through everything you need to know about serverless monitoring: from understanding its importance to implementing best practices that will help you maintain reliable, high-performing serverless applications in 2025 and beyond.
TL;DR:
- Serverless monitoring requires specialized approaches due to limited infrastructure visibility and ephemeral function execution
- Key challenges include cold starts, distributed complexity, and unpredictable costs
- Essential metrics span performance, reliability, resource utilization, and cost tracking
- Effective monitoring combines comprehensive logging, distributed tracing, and proactive alerting
- Tool selection depends on whether you prioritize native cloud integration or multi-cloud visibility
What is serverless monitoring and why is it important?
Unlike traditional architectures where developers maintain direct control over servers, serverless computing delegates infrastructure management to cloud providers like AWS Lambda, Azure Functions, or Google Cloud Functions.
This architectural shift makes monitoring particularly essential for several key reasons:
- Increased complexity: Serverless applications are highly distributed by nature, with functions spread across multiple services and regions
- Limited visibility: You no longer have direct access to the underlying infrastructure, making traditional monitoring approaches ineffective
- Ephemeral execution: Functions may run for mere milliseconds, creating challenges for capturing meaningful performance data
- Cost management: Pay-as-you-go pricing requires vigilant monitoring to prevent unexpected expenses from inefficient code or misconfigurations
Without proper monitoring, your serverless applications risk performance degradation, reliability issues, and unpredictable costs, all of which can significantly impact user experience and business outcomes.
The unique challenges of serverless monitoring
Serverless architectures present several distinct monitoring challenges that don't exist in traditional server-based environments:
| Challenge | Traditional monitoring | Serverless monitoring | Impact |
|---|---|---|---|
| Infrastructure visibility | Full access to servers and system metrics | Black box infrastructure managed by provider | Cannot install traditional agents or access low-level metrics |
| Execution model | Long-running processes | Ephemeral functions (milliseconds to minutes) | Difficult to collect comprehensive performance data |
| Architecture complexity | Monolithic or few large services | Numerous small, specialized functions | Complex request tracing across distributed systems |
| Performance consistency | Predictable warm instances | Cold starts after inactivity periods | Unexpected latency spikes impacting user experience |
| Monitoring standardization | Universal tools and metrics | Vendor-specific capabilities and formats | Fragmented visibility in multi-cloud deployments |
| Resource allocation | Direct control over scaling | Automatic scaling by provider | Limited control over resource optimization |
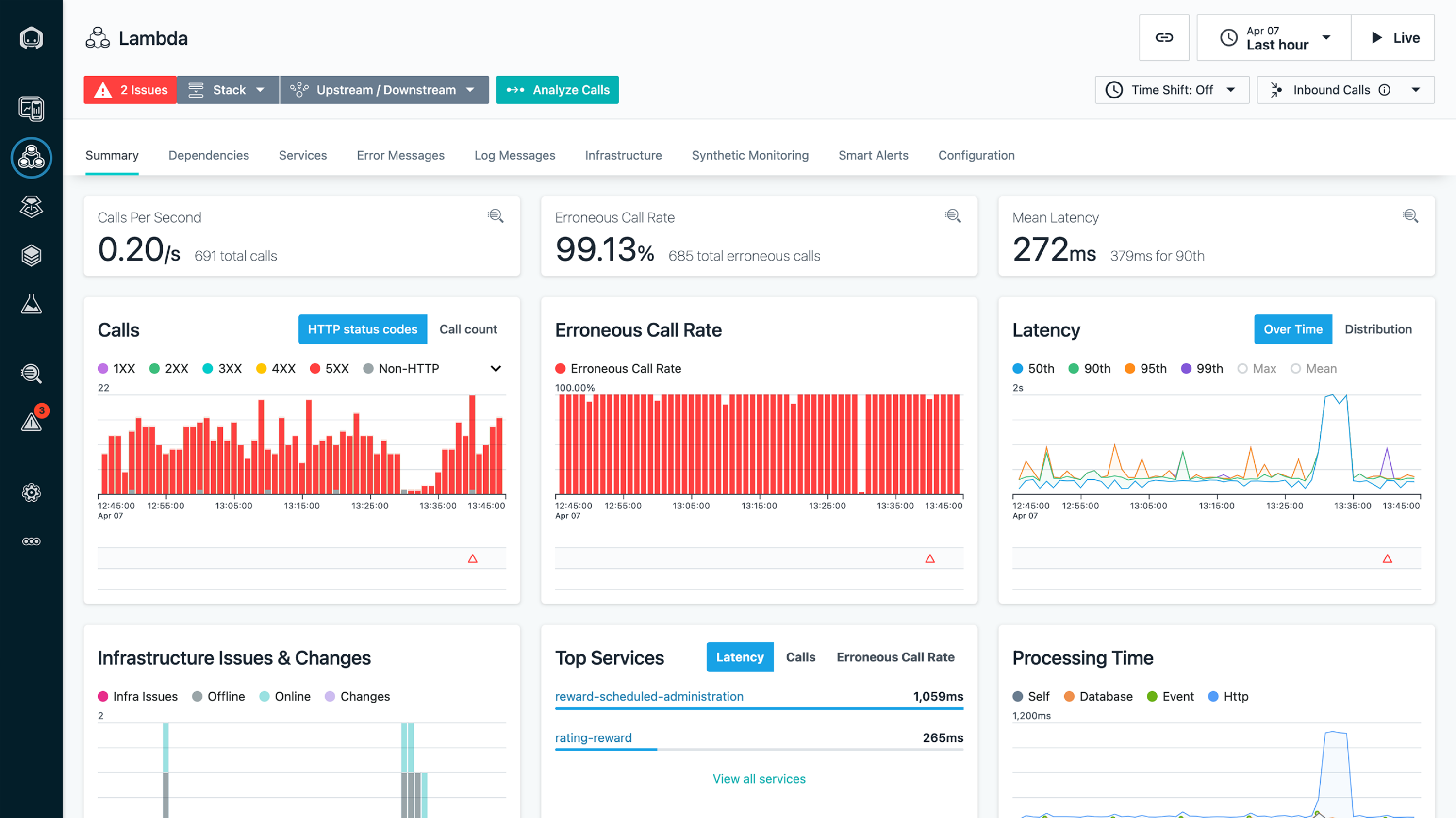
Essential metrics for effective serverless monitoring
To successfully monitor your serverless applications, you need to track specific metrics that provide insights into performance, reliability, and cost:
| Metric category | Key metrics | Importance | Collection method | Monitoring frequency |
|---|---|---|---|---|
| Performance | Execution duration, Cold start latency, End-to-end latency, Throughput | Critical | Native cloud metrics + APM tools | Real-time |
| Reliability | Error rates, Timeout frequency, Throttling occurrences, Success rate | Critical | Cloud provider logs + Custom metrics | Real-time with alerts |
| Resource utilization | Memory usage, CPU utilization, Network traffic, Concurrent executions | High | Cloud provider metrics | Every 1-5 minutes |
| Cost | Invocation count, Billed duration, Memory-seconds, API call costs | High | Billing APIs + Cost management tools | Hourly to daily |
Performance metrics
Industry benchmark: According to AWS, p50 latency for Lambda functions should be under 100ms for optimal user experience, while p99 should remain below 1 second for most applications.
- Execution duration: The time each function takes to complete execution
- Cold start latency: The delay associated with initializing a function after a period of inactivity
- End-to-end latency: The total time from request initiation to response completion. Understanding what constitutes a good API response time is crucial here.
- Throughput: The number of invocations processed per unit of time
Reliability metrics
- Error rates: The percentage of function invocations that result in errors
- Timeout frequency: How often functions exceed their configured timeout limits
- Throttling occurrences: Instances where cloud providers limit function executions due to concurrency limits
- Success rate: The percentage of function executions that complete successfully
Resource utilization
- Memory usage: How much memory each function consumes during execution
- CPU utilization: Processing power used by functions (when available)
- Network traffic: Data transferred in and out of your functions
- Concurrent executions: The number of function instances running simultaneously
Cost metrics
- Invocation count: The total number of function executions
- Billed duration: The actual time you're charged for (typically rounded up)
- Memory-seconds: The product of allocated memory and execution duration
- API call costs: Expenses associated with other cloud services your functions interact with
By consistently tracking these metrics, you can identify performance bottlenecks, troubleshoot errors, optimize resource allocation, and control costs effectively.
Serverless monitoring best practices
ROI insight: Organizations implementing comprehensive serverless monitoring report an average 40% reduction in mean time to resolution (MTTR) and 30% decrease in operational costs through better resource optimization.
Implementing these best practices will help you build a robust monitoring strategy for your serverless applications:
1. Implement comprehensive logging
Proper logging is the foundation of effective serverless monitoring. Since you lack direct server access, logs become your primary window into function behavior:
- Standardize log formats across all functions for easier parsing and analysis
- Include contextual information in logs (request IDs, timestamps, user information)
- Use structured logging (JSON) to make logs machine-readable and queryable
- Configure appropriate log retention policies to balance accessibility with costs
- Centralize logs from all services to create a unified view of your application
For example, in AWS Lambda, you might adopt a structured logging approach:
console.log(
JSON.stringify({
level: 'info',
timestamp: new Date().toISOString(),
requestId: context.awsRequestId,
message: 'Function execution started',
data: { parameters: event },
})
)2. Implement distributed tracing
Distributed tracing allows you to follow requests as they travel through your serverless architecture:
- Add correlation IDs to track requests across multiple functions and services
- Use open standards like OpenTelemetry for vendor-agnostic tracing
- Visualize request flows to identify bottlenecks and dependencies
- Measure latency at each step to pinpoint performance issues
AWS X-Ray integrates natively with Lambda to provide distributed tracing, while third-party tools like Hyperping offer more advanced tracing capabilities that work across multiple cloud providers.
3. Set up proactive alerting
Don't wait for users to report issues, establish alerts that notify you of problems before they impact users:
- Configure alerts for abnormal error rates, latency spikes, and resource constraints
- Set up tiered alert thresholds based on severity and business impact
- Route notifications to the appropriate teams through email, Slack, PagerDuty, etc. Effective DevOps alert management is key.
- Implement alert aggregation to prevent notification fatigue
- Include actionable information in alerts to speed up resolution
4. Monitor cold starts
Cold starts can significantly impact user experience in serverless applications:
- Track the frequency and duration of cold starts across your functions
- Identify patterns and triggers for cold starts
- Implement pre-warming strategies for critical functions
- Optimize function initialization code to reduce cold start duration
- Consider provisioned concurrency for performance-sensitive functions
5. Implement cost monitoring and optimization
Serverless pricing models make cost monitoring particularly important:
- Track function invocation counts and durations at a granular level
- Set up budget alerts to catch unexpected cost increases
- Analyze cost patterns to identify optimization opportunities
- Right-size function memory allocations based on actual usage
- Implement cost allocation tags to attribute expenses to specific teams or features
6. Visualize and dashboard key metrics
Creating effective dashboards helps teams quickly understand application health:
- Build dashboards that combine performance, reliability, and cost metrics
- Include trend analysis to identify gradual degradations
- Create service-level dashboards for specific functions or workflows
- Share dashboards with stakeholders to improve transparency
- Customize views for different team roles (developers, operations, management)
Top serverless monitoring tools for 2025
Several specialized tools can help you implement effective serverless monitoring:
| Tool | Type | Starting Price | Key Features | Pros | Cons |
|---|---|---|---|---|---|
| AWS CloudWatch | Native | Pay-per-use | Basic metrics, logs, dashboards | Deep AWS integration, No setup required | Limited to AWS, Basic features |
| Azure Monitor | Native | Pay-per-use | Metrics, Application Insights, traces | Comprehensive Azure coverage | Azure-specific, Complex pricing |
| Google Cloud Monitoring | Native | Pay-per-use | Metrics, logging, tracing | Good GCP integration | Limited cross-cloud support |
| Datadog | Third-party APM | $15/host/month | Full-stack observability, AI insights | Multi-cloud, Advanced features | Expensive at scale |
| New Relic | Third-party APM | $25/user/month | APM, distributed tracing, analytics | Strong serverless support | Complex pricing model |
| Lumigo | Serverless-specific | $20/million invocations | Auto-tracing, debugging, cost analysis | Purpose-built for serverless | Limited to serverless workloads |
| Hyperping | Uptime monitoring | $5/month | Uptime checks, status pages, alerts | Simple setup, Cost-effective | Focus on availability metrics |
| OpenTelemetry | Open-source | Free | Vendor-neutral observability | No vendor lock-in, Flexible | Requires expertise to implement |
Source: IBM
When selecting a monitoring tool, consider these factors:
- Coverage — Does it support all your serverless platforms and languages?
- Integration — How well does it work with your existing tools and workflows?
- Cost — Is the pricing model suitable for your serverless architecture?
- Ease of use — How quickly can your team become productive with the tool?
- Advanced features — Does it offer capabilities like anomaly detection or auto-remediation?
Implementing effective serverless monitoring: Step by step
Let's walk through a practical approach to implementing serverless monitoring:
| Phase | Action items | Tools needed | Timeline |
|---|---|---|---|
| 1. Define objectives | • Identify critical business metrics • Document SLA) requirements • Prioritize monitoring goals |
Planning tools, stakeholder meetings | Week 1 |
| 2. Establish baselines | • Collect baseline performance data • Define normal operating ranges • Set initial thresholds |
Native cloud metrics, APM tools | Weeks 2-3 |
| 3. Implement instrumentation | • Add monitoring SDKs • Configure structured logging • Implement correlation IDs |
Monitoring libraries, logging frameworks | Weeks 3-4 |
| 4. Configure aggregation | • Set up log aggregation • Build initial dashboards • Configure trace visualization |
Log management tools, dashboard builders | Week 5 |
| 5. Establish alerts | • Define alert thresholds • Configure notification channels • Document response procedures |
Alert management systems | Week 6 |
| 6. Continuous improvement | • Review monitoring data weekly • Refine thresholds monthly • Optimize based on insights |
Analytics tools, team reviews | Ongoing |
Implementation code examples
const AWS = require('aws-sdk')
const cloudwatch = new AWS.CloudWatch()
// Custom metric for business logic
async function recordBusinessMetric(metricName, value) {
await cloudwatch
.putMetricData({
Namespace: 'BusinessMetrics',
MetricData: [
{
MetricName: metricName,
Value: value,
Unit: 'Count',
Dimensions: [
{
Name: 'FunctionName',
Value: process.env.AWS_LAMBDA_FUNCTION_NAME,
},
],
},
],
})
.promise()
}
exports.handler = async (event, context) => {
const startTime = Date.now()
try {
// Function business logic here
const result = await processEvent(event)
// Record success metric
await recordBusinessMetric('SuccessfulProcessing', 1)
// Record processing duration
const duration = Date.now() - startTime
await recordBusinessMetric('ProcessingDuration', duration)
return result
} catch (error) {
// Record error metric
await recordBusinessMetric('ProcessingError', 1)
throw error
}
}Addressing common serverless monitoring challenges
Even with the right tools and practices, you may encounter these common challenges:
Challenge 1: Cold start latency
Cold starts can significantly impact user experience, especially for infrequently accessed functions.
| Solution approach | Pros | Cons |
|---|---|---|
| Provisioned concurrency | Eliminates cold starts completely | Higher costs, requires capacity planning |
| Function warming | Cost-effective for predictable patterns | Complex to implement, not suitable for all workloads |
| Package size optimization | Reduces initialization time, lower costs | May require code refactoring |
| Runtime selection | Some languages start faster | May limit framework choices |
| Container image optimization | Better control over dependencies | Larger deployment packages |
Challenge 2: Debugging distributed errors
When errors occur across multiple serverless functions, identifying the root cause can be challenging.
Step-by-step debugging workflow:
- Identify the error signature: Look for patterns in error messages and affected services
- Collect correlation IDs: Gather all logs related to the failed transaction
- Trace the request flow: Use distributed tracing to visualize the complete path
- Isolate the failing component: Identify which function or service first encountered the error
- Reproduce in test environment: Create minimal test case to reproduce the issue
- Analyze logs and metrics: Examine detailed logs from the failing component
- Implement fix and verify: Deploy correction and monitor for resolution
Consider specialized debugging tools like Lumigo or Thundra for complex distributed issues.
Challenge 3: Cost anomalies
Serverless billing based on execution can lead to unexpected costs if functions misbehave.
| Cost control strategy | Pros | Cons |
|---|---|---|
| Budget alerts | Early warning of overspending | Reactive rather than preventive |
| Concurrency limits | Prevents runaway costs | May impact legitimate traffic |
| Duration monitoring | Identifies inefficient functions | Requires continuous analysis |
| Automatic remediation | Immediate response to issues | Risk of false positives |
| Reserved capacity | Predictable costs | May waste resources if underutilized |
Challenge 4: Log volume management
Serverless applications can generate enormous volumes of logs, leading to high costs and difficulty finding relevant information.
| Log management approach | Pros | Cons |
|---|---|---|
| Log levels | Control verbosity dynamically | May miss important debug info |
| Sampling | Reduces volume while maintaining visibility | Statistical rather than complete picture |
| Retention policies | Automatic cost control | May lose historical data |
| Log filtering | Only store relevant logs | Complex to configure correctly |
| Specialized tools | Advanced search and analysis | Additional cost and complexity |
Challenge 5: Multi-cloud visibility
Organizations using multiple serverless providers face fragmented monitoring visibility.
| Multi-cloud strategy | Implementation complexity | Cost | Flexibility | Vendor lock-in |
|---|---|---|---|---|
| Native tools per cloud | Low | Low | High | High per cloud |
| Single third-party APM | Medium | High | Medium | Low |
| Open-source stack | High | Low (self-hosted) | High | None |
| Hybrid approach | Medium | Medium | High | Medium |
Solutions include:
- Adopt vendor-neutral observability standards like OpenTelemetry
- Use third-party monitoring tools that support multiple cloud providers
- Implement consistent tagging and naming conventions across providers
- Create unified dashboards that aggregate data from all platforms
- Consider tools like Hyperping that provide multi-cloud visibility
Future trends in serverless monitoring
As serverless architectures evolve, monitoring approaches are also advancing. Here are key trends ranked by expected impact:
1. AI-powered observability (Highest impact)
Machine learning algorithms increasingly help identify patterns, predict failures, and automate remediation. Expected mainstream adoption: 2025-2026
- Anomaly detection based on historical patterns
- Predictive alerting for potential issues
- Automatic root cause analysis
- Self-healing systems that respond to detected issues
- Natural language interfaces for monitoring exploration
2. FinOps integration (High impact)
The intersection of finance and operations is becoming critical in serverless environments. Expected integration in most tools: 2025
- Real-time cost optimization recommendations
- Automated resource rightsizing
- Cost impact analysis for code changes
- Granular attribution of costs to features and teams
- Predictive cost modeling based on usage patterns
3. Unified observability (Medium-high impact)
The boundaries between metrics, logs, and traces are blurring. Full convergence expected: 2026-2027
- Seamless navigation between different telemetry types
- Context-preserving workflows across monitoring dimensions
- Correlated alerts that combine multiple signal types
- Unified querying across observability data
- Open standards for telemetry collection and analysis
4. Edge function monitoring (Medium impact)
As serverless expands to edge locations, monitoring must follow. Wide availability expected: 2025-2026
- Geographical performance visualization
- Regional anomaly detection
- Edge-to-origin latency tracking
- Global health dashboards
- Location-aware alerting
Related terms and glossary
Understanding these key terms will help you navigate serverless monitoring more effectively:
Cold start: The initialization delay when a serverless function executes after being idle, including runtime startup and code initialization.
Correlation ID: A unique identifier that tracks a request across multiple services and functions in a distributed system.
Distributed tracing: A method of tracking requests as they flow through multiple services, providing end-to-end visibility.
Ephemeral execution: The temporary nature of serverless function instances that exist only during execution.
Function warming: Techniques to keep serverless functions initialized to avoid cold start delays.
Invocation: A single execution of a serverless function in response to an event or trigger.
Memory-seconds: A billing metric calculated by multiplying allocated memory by execution duration.
Observability: The ability to understand internal system state based on external outputs (logs, metrics, traces).
Provisioned concurrency: Pre-initialized function instances that eliminate cold starts but incur ongoing costs.
Structured logging: Log formatting using consistent schemas (typically JSON) for machine readability.
Throttling: Rate limiting applied by cloud providers when function execution exceeds configured or account limits.
Final thoughts
Effective serverless monitoring is essential for maintaining reliable, high-performing applications in today's cloud-native landscape.
By implementing comprehensive logging, distributed tracing, proactive alerting, and specialized tools, you can overcome the unique challenges of serverless architectures.
For teams looking to simplify their serverless monitoring approach, platforms like Hyperping offer comprehensive monitoring capabilities alongside uptime monitoring and status page functionality. Understanding why you need a status page can further enhance your incident communication.
This integrated approach can significantly reduce the complexity of managing serverless applications while providing the visibility needed to maintain high reliability.
FAQ
What is serverless monitoring and why is it important? ▼
Serverless monitoring is the practice of tracking performance, reliability, and cost metrics for applications built on serverless architectures like AWS Lambda, Azure Functions, or Google Cloud Functions. It's important because serverless applications face unique challenges including increased complexity from distributed systems, limited infrastructure visibility, ephemeral function execution, and pay-as-you-go pricing that requires careful cost management. Without proper monitoring, serverless applications risk performance degradation, reliability issues, and unpredictable costs.
What are the unique challenges of monitoring serverless applications? ▼
Serverless monitoring presents several distinct challenges: limited infrastructure visibility due to the 'black box' nature of cloud provider infrastructure, ephemeral execution where functions may run for just milliseconds making data collection difficult, distributed complexity from numerous specialized functions working together, cold starts that can impact performance, and vendor-specific monitoring that can lead to fragmented visibility in multi-cloud deployments.
What essential metrics should I track for serverless applications? ▼
Essential serverless metrics fall into four categories: Performance metrics (execution duration, cold start latency, end-to-end latency, throughput), Reliability metrics (error rates, timeout frequency, throttling occurrences, success rate), Resource utilization (memory usage, CPU utilization, network traffic, concurrent executions), and Cost metrics (invocation count, billed duration, memory-seconds, API call costs).
What are the best practices for serverless monitoring? ▼
Serverless monitoring best practices include: implementing comprehensive structured logging, setting up distributed tracing with correlation IDs, configuring proactive alerting for anomalies, closely monitoring cold starts, implementing detailed cost monitoring, and creating effective dashboards that visualize key metrics. These practices provide visibility into your serverless applications and help identify issues before they impact users.
What tools are available for serverless monitoring in 2025? ▼
Serverless monitoring tools include cloud provider native options (AWS CloudWatch and X-Ray, Azure Monitor, Google Cloud Monitoring), comprehensive third-party platforms (Datadog, New Relic, Dynatrace), serverless-specific tools (Lumigo, Thundra, Epsagon), uptime monitoring services like Hyperping, and open-source options (OpenTelemetry, Prometheus with serverless exporters, Jaeger). The best choice depends on your specific needs, existing tooling, and whether you use multiple cloud providers.
How do I implement effective serverless monitoring step by step? ▼
Implement serverless monitoring by: 1) Defining clear monitoring objectives based on business needs, 2) Establishing performance baselines and targets, 3) Implementing proper instrumentation with monitoring SDKs and structured logging, 4) Configuring data aggregation and visualization dashboards, 5) Setting up proactive alerts and notifications, and 6) Developing a continuous improvement process to refine your monitoring based on insights.
How can I address cold start latency in serverless functions? ▼
Address cold start latency by: identifying functions with frequent cold starts through monitoring data, considering provisioned concurrency for critical functions, minimizing package size to reduce initialization time, using languages with faster startup times for latency-sensitive operations, and implementing function warming strategies for predictable workloads. Your monitoring system should help identify which functions are most affected by cold starts.
How should I approach debugging distributed errors in serverless applications? ▼
Debug distributed errors in serverless applications by implementing correlation IDs across all functions and services, using distributed tracing to visualize complete request flows, ensuring consistent structured logging throughout your application, recreating error conditions in test environments, and considering specialized debugging tools like Lumigo or Thundra that are designed specifically for serverless environments.
How can I monitor and control costs in serverless applications? ▼
Monitor and control serverless costs by implementing budget alerts and cost anomaly detection, setting concurrency limits to prevent runaway functions, closely tracking function durations and memory usage, implementing automatic remediation for cost-related issues, and using reserved concurrency to limit expensive functions. Regular reviews of cost patterns can help identify optimization opportunities.
What future trends are emerging in serverless monitoring? ▼
Emerging trends in serverless monitoring include: AI-powered observability with anomaly detection and predictive alerting, FinOps integration for real-time cost optimization, unified observability that blends metrics, logs and traces, and edge function monitoring capabilities as serverless expands to edge locations. These advancements will help organizations better manage increasingly complex serverless architectures.



