Every minute matters when you're dealing with a security incident. The longer a breach goes undetected and unresolved, the more damage it can cause to your systems, data, and reputation.
But traditional incident response is plagued with challenges: alert fatigue, manual processes, skill shortages, and the sheer complexity of modern IT environments. Security teams are drowning in alerts while struggling to respond quickly enough to the threats that matter.
Fortunately, there's a solution that's transforming how organizations handle security incidents: automation.
TL;DR
- Incident response automation uses AI, machine learning, and rule-based workflows to detect, analyze, and remediate security incidents with minimal human intervention
- Key benefits include 33% faster resolution times, reduced alert fatigue, average savings of $3.05 million per breach, and consistent responses at scale
- Four core components work together: detection and alerting, classification and prioritization, automated remediation, and post-incident analysis
- Implementation success requires starting small with high-value use cases, integrating existing tools, building tested playbooks, and maintaining human oversight
- Essential tools include comprehensive platforms (SOAR solutions), specialized monitoring like Hyperping, and analytics systems tailored to your organization's needs
In this post, we'll explore everything you need to know about incident response automation, including:
- What it is and why it matters
- Core components
- Key benefits
- Tools and platforms
- Implementation best practices
- Challenges and solutions
What is incident response automation, and why does it matter?
Incident response automation leverages AI, machine learning (ML), and rule-based workflows to detect, analyze, and remediate security or operational incidents with minimal human intervention. At its core, it's about using technology to handle repetitive, time-consuming tasks in the incident response process, allowing your security team to focus on more complex problems that require human judgment and expertise.
Automated incident response matters for several critical reasons:
- Speed is critical: In security, minutes or even seconds can make the difference between a minor incident and a major breach. You can calculate the cost of downtime to understand the financial impact of delayed responses.
- Alert volumes are overwhelming: The average organization faces thousands of security alerts daily, making manual triage impossible
- Skill shortages are real: There simply aren't enough cybersecurity professionals to go around
- Consistency saves lives: Human responders might miss steps or make different decisions when facing similar incidents
- Scale is non-negotiable: As your organization grows, your ability to respond to incidents must scale accordingly
Without automation, organizations struggle to keep pace with the threat landscape. Security teams become overwhelmed, incidents slip through the cracks, and response times stretch from minutes to hours or even days.
In contrast, automation can help you identify and contain threats in seconds or minutes, dramatically reducing the potential impact of security incidents.
Source: Australian Cyber Security Centre
Core components of incident response automation
A comprehensive incident response automation system brings together four essential components that create a seamless, efficient process for managing security incidents from detection through resolution.
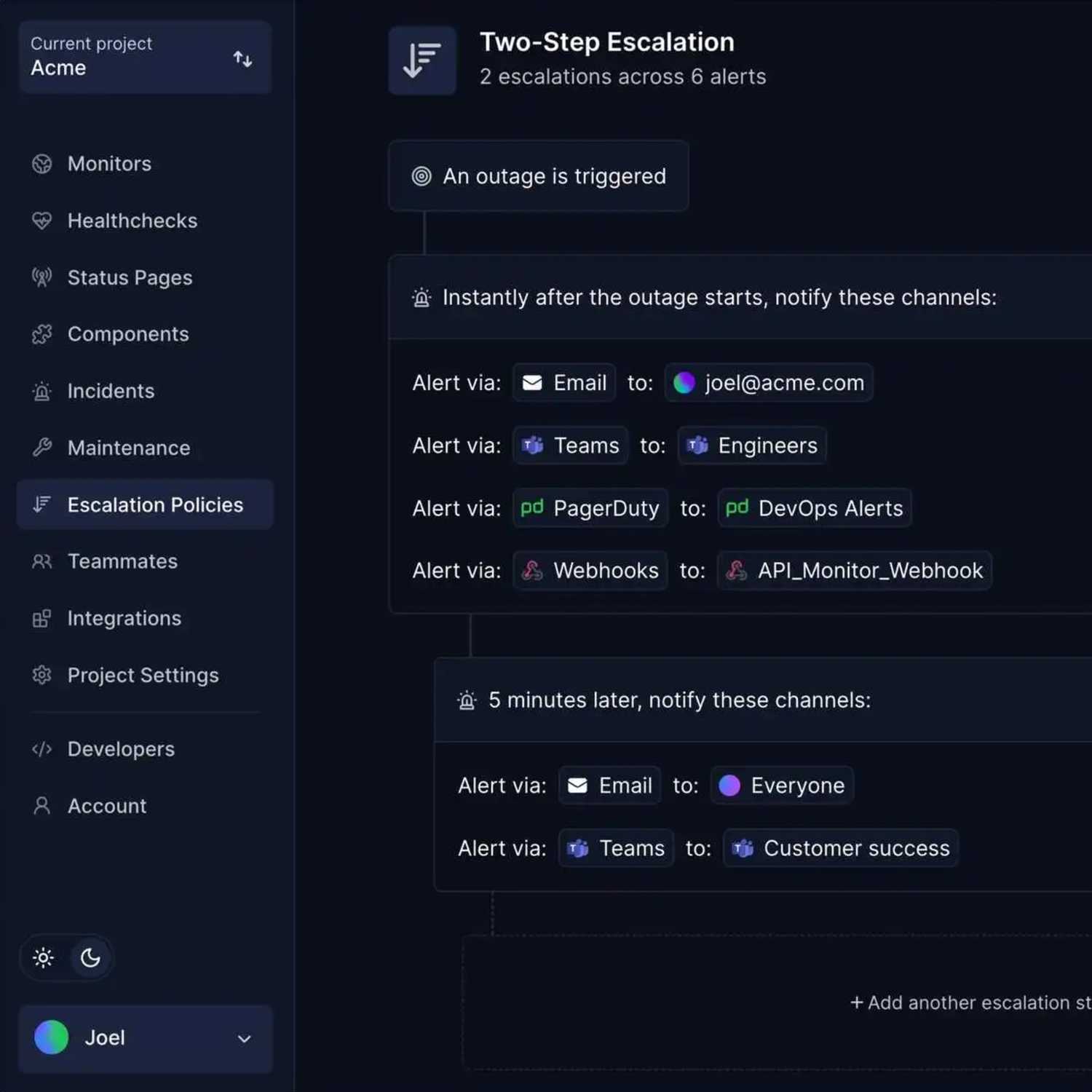
1. Detection and alerting
The automation journey begins with continuous monitoring of your entire digital environment. Automated systems constantly scan networks, applications, and endpoints for anomalies that could indicate security incidents.
This component uses a combination of signature-based detection (looking for known patterns of malicious activity) and behavior-based detection (identifying unusual activities that deviate from established baselines). The MITRE ATT&CK Framework provides a comprehensive knowledge base of adversary tactics and techniques that can inform your detection rules.
Alert volumes at scale: Organizations receive an average of 11,000 security alerts per day, with 32% going uninvestigated due to resource constraints. Automated detection and intelligent filtering are no longer optional.
When potential threats are identified, whether they're phishing attempts, malware downloads, unusual login patterns, or data exfiltration, the system generates alerts in real-time, ensuring nothing flies under the radar.
Platforms like Hyperping play a critical role in this phase, offering continuous uptime monitoring through browser checks, cron job monitoring, SSL certificate validation, port monitoring, and keyword monitoring. These capabilities ensure that potential availability issues (often the first sign of a security incident) are detected immediately.
2. Classification and prioritization
Not all security incidents are created equal. Some require immediate attention, while others can wait.
Automated classification and prioritization systems categorize incidents by severity using predefined criteria. This ensures your security team focuses on the most urgent issues first, rather than being distracted by less significant alerts.
| Severity level | Evaluation criteria |
|---|---|
| Critical | Active breach, data exfiltration in progress, widespread system compromise, imminent business impact |
| High | Confirmed malware infection, unauthorized access to sensitive systems, exploited vulnerability with public exploit |
| Medium | Suspicious activity patterns, failed intrusion attempts, misconfigurations exposing attack surface |
| Low | Policy violations, minor security events, informational alerts, potential false positives |
3. Automated remediation
Once an incident is detected and classified, predefined workflows (often called playbooks or runbooks) can execute appropriate response actions automatically. These might include:
- Isolating infected systems from the network
- Blocking malicious IP addresses or URLs
- Forcing password resets for compromised accounts
- Capturing forensic data for later analysis
- Deploying patches or configuration changes
- Notifying relevant stakeholders through incident communication templates
The level of automation can vary based on your organization's comfort level, from fully automated responses for common, low-risk incidents to partial automation that prepares information for human analysts handling more complex situations.
4. Post-incident analysis
After an incident is resolved, automated systems compile comprehensive data for root-cause analysis. This includes:
- Timeline of events
- Actions taken during response
- Effectiveness of controls
- Areas for improvement
- Updated threat intelligence
This data enables continuous improvement through a DevOps feedback loop approach, ensuring your team learns from each event and strengthens defenses accordingly. Organizations should conduct thorough incident post-mortems to extract maximum value from each incident.
By integrating these four components, incident response automation creates a cycle of detection, response, and improvement that enhances your security posture over time.
Key benefits of automated incident response
Implementing incident response automation delivers substantial advantages that can transform your security operations:
- Faster resolution: Reduce MTTD and MTTR by up to 33%
- Reduced alert fatigue: AI-driven analysis minimizes false positives that overwhelm analysts
- Cost savings: Average of $3.05 million saved per breach compared to manual response
- Effortless scaling: Handle growing alert volumes without proportional staffing increases
- Consistent responses: Eliminate variability with standardized best practices
Faster resolution times
Perhaps the most significant advantage of automation is speed. Automated systems can detect and respond to threats in seconds or minutes, whereas manual processes might take hours or days.
Speed matters: Organizations using incident response automation reduce their Mean Time to Detect (MTTD) and Mean Time to Resolve (MTTR) by up to 33%. This dramatic improvement can be the difference between a minor security event and a catastrophic breach.
Google's SRE practices demonstrate how automated incident detection and response at scale can maintain service reliability while minimizing human toil.
Reduced alert fatigue
Security tools generate thousands of alerts daily, many of which are false positives. This constant noise leads to alert fatigue, where analysts become desensitized to warnings and might miss genuine threats.
AI-driven analysis minimizes false positives by correlating data from multiple sources and learning from past incidents. This ensures analysts only see meaningful alerts that require attention, significantly reducing burnout and improving morale. Implementing proper DevOps alert management practices is essential for maintaining team effectiveness.
Cost efficiency
Automating repetitive tasks delivers substantial cost savings. Instead of having highly-paid security analysts performing routine activities like alert triage or data collection, automation handles these tasks, allowing your DevOps team to focus on complex problems that truly require human expertise.
Cost impact: Organizations with automated security responses saved an average of $3.05 million per breach compared to those without automation (2023 IBM Cost of a Data Breach Report). Understanding the legal implications of a data breach is also crucial, as these can significantly add to the overall cost.
Additionally, faster incident resolution reduces the financial impact of breaches. You can use an SLA calculator to understand how improved response times affect your service commitments.
Scalability
As your organization grows, your attack surface expands, potentially leading to more security incidents. Unlike human teams, automated systems can scale effortlessly to handle increasing volumes of alerts without additional resources.
This scalability ensures your security operations can grow with your business without compromising effectiveness or requiring proportional increases in staffing.
Consistency
Humans, even expert analysts, might respond differently to similar incidents based on their experience, workload, or other factors. Automation ensures every incident is handled according to established best practices, eliminating variability in the response process.
This consistency is especially valuable during high-stress situations or when regular team members are unavailable, ensuring nothing falls through the cracks.
Tools and platforms for incident response automation
The market offers a variety of tools to support your incident response automation efforts. Selecting the right combination depends on your organization's size, existing infrastructure, and specific security needs.
Comprehensive security platforms
| Tool | Key features | Best for |
|---|---|---|
| CrowdStrike Falcon | Unified EDR/XDR capabilities with automated threat hunting and response | Large enterprises with complex environments |
| Palo Alto Cortex XSOAR | Security orchestration with 500+ integrations and visual playbook editor | Organizations seeking extensive automation capabilities |
| IBM Security QRadar SOAR | Case management with built-in threat intelligence and guided responses | Enterprises with existing IBM security investments |
Specialized solutions
| Tool | Key features | Best for |
|---|---|---|
| Hyperping | Comprehensive uptime monitoring with browser checks, cron job monitoring, SSL monitoring, and automated status pages | DevOps and SRE teams in startups focused on system reliability |
| Cynet | Endpoint protection with customizable pricing and automated triage | Small to midsize businesses with limited security resources |
| Tines | No-code automation platform with flexible workflows and easy integration | Security teams that need customizable automation without coding |
Analytics and detection tools
| Tool | Key features | Best for |
|---|---|---|
| Splunk | Powerful log analysis with AI/ML capabilities for threat detection | Organizations with large data volumes requiring deep analysis |
| Elastic Security | Open core SIEM with built-in detection rules and response actions | Teams looking for flexibility and customization |
| LogRhythm | User and entity behavior analytics with automated response suggestions | Organizations prioritizing insider threat detection |
For a comprehensive comparison of available options, review the best incident management tools in the market.
Key selection criteria
When choosing tools for your incident response automation strategy, evaluate:
- Integration capabilities with your existing security stack
- Ease of use for building and maintaining automation workflows
- Scalability to handle your organization's alert volume
- Reporting features for compliance and improvement tracking
- Support for compliance frameworks relevant to your industry
Remember that no single tool does everything perfectly. Many organizations use a combination of platforms to create a comprehensive automation ecosystem.
Implementing incident response automation: A step-by-step guide
Successfully implementing incident response automation requires careful planning and execution. This phased approach minimizes risk while maximizing value, allowing you to build confidence and expertise gradually before expanding to more complex use cases.
1. Define incident types and response workflows
Begin by cataloging the types of incidents your organization commonly faces. These might include:
- Phishing attempts
- Malware infections
- Unauthorized access
- Data exfiltration
- Denial of service attacks
- Misconfigurations
- Application vulnerabilities
- System outages and availability issues
For each incident type, document the ideal response workflow (the specific steps that should be taken from detection through resolution). Include decision points, required approvals, and criteria for escalation.
This documentation forms the foundation for your automation playbooks and ensures you're automating the right processes in the right way.
2. Assess automation readiness
Before diving into implementation, evaluate your organization's readiness for automation. Consider:
- Maturity of existing processes: Are your manual incident response procedures well-defined and consistently followed?
- Data quality: Do you have reliable, timely data feeding into your security systems?
- Integration capabilities: Can your current security tools communicate with each other and with automation platforms?
- Team skills: Does your security team have the expertise to build and maintain automation workflows?
This assessment helps identify gaps that need addressing before automation can succeed and sets realistic expectations for what can be automated immediately versus longer-term goals.
3. Start small with high-value use cases
Resist the temptation to automate everything at once. Instead, identify high-value, low-risk processes for your initial automation efforts. Good candidates include:
- Alert triage and enrichment
- Evidence collection
- Known malware containment
- User account lockouts
- Vulnerability scanning
- Uptime monitoring and availability checks
These processes offer tangible benefits with minimal risk if automation doesn't work perfectly. Success with these initial use cases builds confidence and provides learnings for more complex automation.
4. Integrate existing tools
Effective incident response automation requires seamless communication between your security tools. Focus on integrating:
- SIEM systems
- Endpoint protection platforms
- Network security devices
- Threat intelligence feeds
- Ticketing systems
- Communication platforms
- Uptime monitoring services like Hyperping
Most modern security tools offer APIs or pre-built integrations with popular automation platforms. Leverage these capabilities to create a unified ecosystem where information flows freely between systems.
Hyperping, for example, can integrate with your incident response workflows to automatically trigger alerts when system availability issues are detected, feeding critical information directly into your automation platform. For cloud-native environments, consider implementing Kubernetes monitoring and serverless monitoring to ensure comprehensive coverage.
5. Build and test automation playbooks
With integrations in place, develop automated playbooks for your priority incident types. The MITRE ATT&CK Framework can help inform your triggers and detection logic based on known adversary behaviors.
Each playbook should include:
- Triggers that initiate the workflow
- Actions to be taken at each step
- Decision points based on gathered data
- Escalation criteria for when human intervention is required
- Expected outcomes and success metrics
Test these playbooks thoroughly in a non-production environment before deployment. Use simulated incidents to verify each step works as expected and that playbooks handle edge cases appropriately.
6. Implement with human oversight
When first deploying automation, maintain close human oversight. Consider implementing automation in stages:
| Stage | Automation level | Human involvement | Best for |
|---|---|---|---|
| Stage 1 | Automation suggests actions | Analysts review and execute manually | Initial deployment, building trust, high-risk actions |
| Stage 2 | Low-risk actions execute automatically | Approval required for high-impact actions | Standard incidents, proven playbooks |
| Stage 3 | Full automation for routine incidents | Monitoring and periodic review only | Well-understood incidents, mature processes |
This phased approach builds trust in the automation system while providing opportunities to refine workflows before full deployment. Google's SRE practices offer valuable guidance on balancing automation with appropriate human oversight.
7. Measure, refine, and expand
Establish metrics to evaluate the effectiveness of your automation efforts, such as:
- Reduction in MTTD and MTTR
- Percentage of incidents handled automatically
- Analyst time saved
- False positive reduction
- Consistency of response
- System uptime and availability
Use these metrics as part of a DevOps feedback loop to identify areas for improvement, refine existing playbooks, and guide the expansion of automation to additional incident types and response actions.
Implementation timeline summary
| Step | Timeframe | Key deliverable | Risk level |
|---|---|---|---|
| 1. Define workflows | 2-4 weeks | Documented incident types and response procedures | Low |
| 2. Assess readiness | 1-2 weeks | Readiness assessment report with gap analysis | Low |
| 3. Start small | 2-4 weeks | Initial use cases identified and prioritized | Low |
| 4. Integrate tools | 4-8 weeks | Integrated security tool ecosystem with API connections | Medium |
| 5. Build playbooks | 4-6 weeks | Tested automation playbooks for priority incidents | Medium |
| 6. Implement with oversight | 8-12 weeks | Phased automation deployment with monitoring | Medium-High |
| 7. Measure and refine | Ongoing | Performance metrics and continuous improvement | Low |
Challenges and solutions in incident response automation
While automation offers tremendous benefits, implementing it successfully isn't without challenges. Organizations should anticipate these common obstacles and apply proven strategies to overcome them.
| Challenge | Impact level | Solution difficulty | Time to resolve |
|---|---|---|---|
| Accuracy concerns | High | Medium | 3-6 months |
| Evolving threats | High | High | Ongoing |
| Integration complexity | Medium | Medium-High | 2-4 months |
| Organizational resistance | Medium | Low-Medium | 1-3 months |
| Implementation complexity | Medium | Medium | 3-6 months |
Accuracy concerns
Challenge: Automation systems may generate false positives or negatives, potentially missing critical incidents or wasting resources on non-issues.
Solution:
- Implement a feedback loop where analysts report automation errors
- Continuously tune detection rules based on performance data
- Use AI/ML systems that improve with additional training data
- Maintain human oversight for high-impact decisions
- Deploy reliable monitoring tools like Hyperping that reduce false positives through accurate detection methods
Evolving threats
Challenge: Threat actors constantly develop new techniques that automated systems may not recognize.
Solution:
- Subscribe to threat intelligence feeds that update your automation system
- Regularly review and update detection rules and response playbooks
- Implement behavior-based detection alongside signature-based approaches
- Schedule periodic red team exercises to test automation effectiveness
- Reference the MITRE ATT&CK Framework to stay current with adversary tactics
Integration complexity
Challenge: Connecting disparate security tools into a cohesive automation ecosystem can be technically challenging.
Solution:
- Prioritize tools with rich API capabilities and pre-built integrations
- Consider security platforms that offer built-in automation features
- Use integration platforms (iPaaS) to bridge gaps between systems
- Document integrations thoroughly for troubleshooting and knowledge transfer
- Start with fewer integrations and expand gradually
Organizational resistance
Challenge: Team members may resist automation due to concerns about job security or skepticism about its effectiveness.
Solution:
- Emphasize how automation handles routine tasks so analysts can focus on more interesting work
- Start with automating the most tedious, repetitive tasks that analysts dislike
- Share success metrics demonstrating the value of automation
- Involve security analysts in the design and testing of automation workflows
- Provide training opportunities to help team members develop new skills for managing automated systems
Complexity of implementation
Challenge: Setting up effective automation requires significant time and expertise initially.
Solution:
- Break implementation into manageable phases with clear milestones
- Consider starting with pre-built automation templates from vendors
- Invest in training for team members responsible for automation
- Partner with experienced consultants for initial setup if internal resources are limited
- Focus on quick wins to demonstrate value and build momentum
By anticipating these challenges and implementing thoughtful solutions, you can navigate the potential pitfalls of incident response automation and realize its full benefits.
The future of incident response automation
As threats continue to advance and technology improves, incident response automation will become increasingly sophisticated.
Key developments on the horizon:
- Advanced AI capabilities: Predictive analytics, natural language processing, and autonomous response systems
- Global threat intelligence: Real-time updates, adversary behavior analysis, and industry-specific intelligence
- Expanded operational scope: IT operations, compliance, privacy breaches, and supply chain security
AI and machine learning advancements
Next-generation incident response systems will leverage more advanced AI capabilities, including:
- Predictive analytics that identify potential incidents before they occur
- Natural language processing for extracting intelligence from unstructured data
- Autonomous response systems that adapt to new threats without human programming
- Anomaly detection that identifies novel attack patterns with minimal false positives
These technologies will enable automation to handle increasingly complex incidents while requiring less human oversight.
Integration with threat intelligence
Automation systems will more tightly integrate with global threat intelligence networks, enabling:
- Real-time threat updates that immediately adjust detection and response parameters
- Adversary behavior analysis that anticipates attacker's next moves
- Industry-specific intelligence tailored to your organization's risk profile
- Automated threat hunting based on emerging indicators of compromise
The MITRE ATT&CK Framework will continue to serve as a foundation for standardizing threat intelligence integration across platforms.
Expanded scope beyond security
Incident response automation will expand beyond traditional security use cases to encompass:
- IT operations incidents like outages and performance issues
- Compliance violations and regulatory reporting requirements
- Privacy breaches and data protection concerns
- Supply chain security events affecting vendors and partners
This broader scope will create a unified approach to managing all types of organizational incidents, improving overall resilience.
Key terms and definitions
Understanding the terminology is essential for implementing effective incident response automation.
| Term | Definition in incident response automation context |
|---|---|
| SOAR | Security Orchestration, Automation and Response platforms that integrate security tools and automate incident workflows |
| SIEM | Security Information and Event Management systems that collect and analyze security data from across your environment |
| MTTD | Mean Time to Detect, the average time it takes to identify a security incident from when it begins |
| MTTR | Mean Time to Resolve, the average time from incident detection to complete resolution |
| Playbook | A predefined set of automated actions and decision points that respond to specific incident types |
| Runbook | Detailed step-by-step procedures for handling incidents, which can be partially or fully automated |
| EDR/XDR | Endpoint Detection and Response / Extended Detection and Response tools that monitor and respond to threats across endpoints and other systems |
| False positive | An alert that incorrectly identifies normal activity as a security threat, wasting analyst time |
| Alert fatigue | The desensitization that occurs when analysts are overwhelmed by too many alerts, causing them to miss genuine threats |
| Threat intelligence | Information about current and emerging security threats, used to inform detection rules and response actions |
Making incident response automation work for you
The benefits are clear: faster resolution times, reduced alert fatigue, cost savings, consistent responses, and the ability to scale with growing threats. However, successful implementation requires careful planning, the right tools, and a methodical approach.
Hyperping's role in automated incident response: Continuous uptime monitoring through browser checks, cron job verification, SSL certificate validation, and more. When integrated into your automation workflows, these capabilities ensure availability issues (often the first sign of security incidents) are detected and addressed immediately.
Detection is the foundation of any effective incident response strategy. Tools like Hyperping play a crucial role here, providing continuous uptime monitoring through browser checks, cron job verification, SSL certificate validation, and more.
When integrated into your automation workflows, these monitoring capabilities ensure that availability issues (often the first sign of security incidents) are detected and addressed immediately.
Beyond detection, Hyperping's status page functionality enables transparent communication with customers during incidents. Organizations can choose between public and private status pages to match their communication needs, or use internal status pages for team coordination. Features like incident insights provide valuable post-incident data. This automated communication is a critical but often overlooked component of incident response, helping maintain trust even when problems occur.
FAQ
What is incident response automation? ▼
Incident response automation leverages AI, machine learning, and rule-based workflows to detect, analyze, and remediate security or operational incidents with minimal human intervention. It handles repetitive tasks in the incident response process, allowing security teams to focus on complex problems requiring human judgment.
Why is incident response automation important for organizations? ▼
Incident response automation is crucial because: 1) It dramatically reduces detection and response times, 2) It helps manage overwhelming alert volumes, 3) It addresses cybersecurity skill shortages, 4) It ensures consistent responses to similar incidents, and 5) It enables security operations to scale with organizational growth.
What are the core components of incident response automation? ▼
A comprehensive incident response automation system consists of four essential components: 1) Detection and alerting for continuous monitoring, 2) Classification and prioritization to categorize incidents by severity, 3) Automated remediation through predefined workflows, and 4) Post-incident analysis for continuous improvement.
What benefits does automated incident response provide? ▼
Key benefits include faster resolution times (reducing MTTD and MTTR by up to 33%), reduced alert fatigue, cost efficiency (saving an average of $3.05 million per breach), scalability to handle growing alert volumes, and consistency in handling security incidents according to established best practices.
What tools are available for incident response automation? ▼
The market offers various tools including comprehensive security platforms (CrowdStrike Falcon, Palo Alto Cortex XSOAR, IBM Security QRadar SOAR), specialized solutions (Hyperping, Cynet, Tines), and analytics tools (Splunk, Elastic Security, LogRhythm). The best choice depends on your organization's specific needs and existing security infrastructure.
How should organizations implement incident response automation? ▼
Implementation should follow a structured approach: 1) Define incident types and response workflows, 2) Assess automation readiness, 3) Start with high-value, low-risk use cases, 4) Integrate existing security tools, 5) Build and test automation playbooks, 6) Implement with human oversight, and 7) Continuously measure, refine, and expand automation capabilities.
What challenges might organizations face with incident response automation? ▼
Common challenges include accuracy concerns (false positives/negatives), keeping up with evolving threats, integration complexity between different security tools, organizational resistance to automation, and the initial complexity of implementation. Each challenge can be addressed with appropriate strategies and planning.
How does uptime monitoring relate to incident response automation? ▼
Uptime monitoring tools like Hyperping play a critical role in the detection phase of incident response by continuously checking system availability through browser checks, cron job monitoring, SSL certificate validation, and other methods. Availability issues are often the first sign of security incidents, making reliable monitoring an essential component of effective automation.
What does the future of incident response automation look like? ▼
The future will bring more advanced AI capabilities (predictive analytics, natural language processing, autonomous response), tighter integration with global threat intelligence, and expanded scope beyond traditional security use cases to include IT operations, compliance, privacy, and supply chain security incidents.
Can small organizations benefit from incident response automation? ▼
Yes, small organizations can benefit significantly from automation by starting with specialized solutions focused on their most critical needs. They can implement automation gradually, beginning with high-value processes like alert triage, evidence collection, and uptime monitoring, then expanding as their security maturity grows.